PaddleYOLO训练自己的数据集
近期一直在研究毕业设计,在其中,我涉及到了PaddleYOLO的训练和部署,在网上的教程较少,经过不断努力,我也算是跑出来了,所以在这里分享出来做个记录,防止下次使用又忘记了怎么搞。
人的精力是有限的,能做的事情不多,然而我总想做更多的事情,甚至不加排序的做这些事情,最终碌碌无为。
我与平庸同行,虽然厌恶他,但平庸从未嫌弃我的能力,始终保持着最平易近人的方式环抱着我。
平庸没有给我带来负面情绪,在我焦虑几近崩溃时积极调整,在我决心要做某些事情时他默默退出从未说过你不行。
但是我的潜意识里有很多他的影子,保持乐观不要过度悲伤,保持善良不要急功近利,保持健康不要没了青山。
已然接受了自己的平庸,在今后的道路上也许会有闪光,但平庸才是最长情的那个。
现在写公众号晚不晚,我觉的是有些晚的。但无论是什么时候开始都会遇到各种各样的问题。公众号推荐模式早已发生改变,给普通人留了很多机会。
机会有了,就去做。没有什么经验的我,运营公众号表现的依然是个小白。目前还停留在内容运营,但我却选了如此小众的方向——独立博客。
在公众号里面讲独立博客似乎是逆势而为,发布的文章阅读量从未突破两位数,看了很多账号差不多如此,等待着掉入流量池。做公众号有点玄学味道,但是也看到有人动不动就注销关注数过万的账号,另起炉灶也能很快有所成。如此来看,做公众号还是有一套方法的,至于是啥要付费才能明白。公众号还是卖课的比较多啊。
而我现在要做的是积累内容,但精力有限,每周仅发布3篇文章,这样算下来要积累100篇文章也需要200多天。现在写作的能力有限,光是找选题都能用很多时间,再列大纲,再写正文,再优化语言,这一套流程下来需要七八个小时。
接下来是想办法优化时间。
3月份骑行次数和里程都不多,主要原因是后拨变速异常,拖了很久才处理。调整尾钩变形、后拨更换了导轮,终于把后拨变速搞好了,骑上去明显感觉不一样。
不多说,看看数据:
| 总里程 | 310.33km |
| 总时长 | 15:10:29 |
| 骑行次数 | 28 |
| 月均速 | 20.45km/h |
这数据没眼看,到目前还没有恢复去年的水平。有点动摇,要不要再升级自行车,中轴、轮组都给换掉,还是直接买个入门公路车。
但有考虑到骑车健身,不能一味追求速度,当前的问题是骑车锻炼时间的不足,根据精力合理安排骑行时间。
从产生买相机的念头,到买相机,前前后后有一个多月。这个过程潜意识在帮我做决定,入门相机还是进阶相机,潜意识帮我选择入门型。
入门相机确实符合我的需求,毕竟技术水平在那里,拿再好的相机很难拍出惊艳的照片。入门相机则可以让我快速上手,多练习拍照技巧,找找大师机位,看看能不能拍出大师的感觉。
虽然不拍视频,但我还是入手了更适合拍视频的索尼ZV-E10Ⅱ,使用固定机位录个口播也不错,怪不得导购说拿来做直播也是不错的选择。
相机到手,接下来要练习拍照,找找教程跟着学习,第一时间拍出第一张照片。

该脚本基于 Strava API v3 获取指定用户当年的所有骑行活动数据,并将其保存为JSON格式
Strava Riding Api 只实现了 OAuth 2.0 授权流程的部分自动化,由于技术限制,目前无法实现完全自动化:
已实现部分
重要: 在使用此脚本前,请确保在Strava开发者平台上正确配置您的应用:
localhost
注意:只需输入 localhost 而不是完整的 http://localhost:8000
yarn install
yarn auth
获取授权后,您会收到一个授权码。将其粘贴到命令行中。
yarn start
strava_data.json如果您遇到API相关错误,请尝试以下解决方案:
yarn auth
重新获取授权并更新令牌
检查API状态:
访问 Strava API状态 确认服务是否正常
localhost作为授权回调域
本项目采用 Mozilla 公共许可证 2.0 版发布
Strava API v3:https://developers.strava.com/docs/reference
Strava Riding Api:https://github.com/achuanya/Strava-Riding-Api
![]()
就在刚刚 EasyFill 终于通过了 Chrome Web Store 的审核,正式发布了!
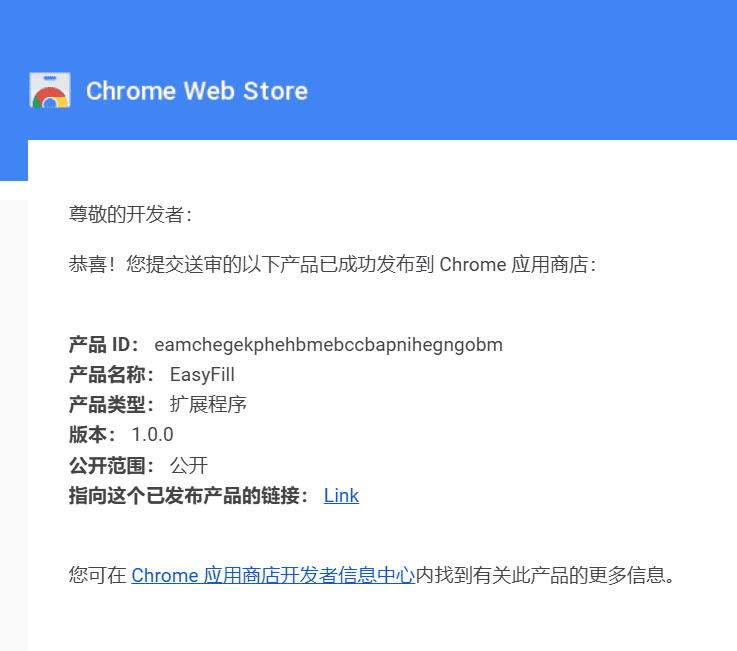
EasyFill。查看 更新日志 了解最新功能和修复。
如果你在使用过程中遇到问题,请在我的博客留言。
感谢您对我的支持,本人非程序员,忙里抽闲,为爱发电。
如果您觉得 EasyFill 对您有帮助,可以通过以下方式支持我继续创作:

本项目基于 Mozilla Public License Version 2.0。
Github 仓库:https://github.com/achuanya/EasyFill
✨ EasyFill 只为向那些在浮躁时代,依然坚守独立博客精神的你们致敬!

昨天跟老板去了学校的一个生物医学的中心,正好参观了那边的老鼠房。
老鼠房就是集中饲养实验用动物的地方。我虽然知道做生物医学的人大多用老鼠,也知道老鼠房,但是我从来不愿意去打听,更不用说是参观了。生物课题周期长,复现难,出成果更是以数年为计算单位,是我一点也不愿意沾染的领域。奈何现在的老板做相关课题,也就摊上了参观这档子事。
一开门就是浓烈扑鼻的鱼虾的味道,直冲脑门。他们纷纷解释说是老鼠食物的味道,真是一秒也不能忍受,太令人作呕了。合理怀疑不只是鱼虾,养动物再干净多少有些体味的。老鼠在小盒子里,密密麻麻放满了架子。介绍的老师说:这就是老鼠的旅馆,没什么的。
外面走廊上正好路过两架空盒子,送去清洗房——谁家好“旅馆”住两天要你命?
我没害过老鼠,但目前有两只为我而死。第一只因为我发明了一种测试的方法,老板让我去眼角膜上试试。找了合作的眼科中心的老师,那天他拿出来一只老鼠,一捏一挤,取了它的眼睛。活的眼角膜剥出来,养在培养皿里,我不过试了两三分钟,就发现检测方法不能适用活体眼角膜。没有数据,也无进展。
第二只依然是为了试用我发明的那劳什子检测方法。这回阵仗可大,五个人围着。做手术的医生把老鼠脑子用电锯切开,助手在旁边吸血水递工具,乒乒乓乓忙了一下午。显微镜递给我,让我看耳蜗找到了,老鼠全麻着,脑壳开着,躺在手术台上,身体还随着呼吸微微起伏。我连好电极,让医生帮我把电极插进去,医生满头满身都是汗,没好气地直接走了:你要插什么,弄什么,自己弄去,反正要找的地方也都已经给你找到了。
助手捧着毛巾水,急急追出去照顾医生。100微米粗细的电极插老鼠耳蜗,我插了两遍,一看到老鼠微微眯着眼看我,血淋淋躺着,实在手抖的厉害。最后让电极制作组的男博士做了这个固定电极的工作,我去电脑上控制测试了。
结果还算好,这只老鼠没白死。
为我而死的老鼠目前也只有这两只。我爱养动物,实在下不去手。但我读博时有位生物的好友S,最爱在吃午饭的时候跟我细数今天杀了多少老鼠,怎么杀的,如何敲掉老鼠前指后趾标记号码。我不爱听,她恶趣味,偏要细说。她做基因工程,经常提到过修改某基因的老鼠确实变聪明了。
去过老鼠房之后,忍不住问起另一位还在日本做生物的好友L,是不是老鼠房都这么大味道。她说她那边还行。又说自己下个月要去英国一个月,老鼠还没找到人照顾。我想起家里鹦鹉:要是我还在日本,可以帮你养。
她:我有四百个老鼠。
我:…
看来她也杀了不少,只是不说。倒显得我矫情了,对于生物人而言不过是样品而已。
晚上下了班打开电脑刚坐下就看到了一封 Google 邮件,首先看到了发件人 “Chrome Web Store”,当时就心想提交审核一个多星期了,终于看到一点音信了。点开后,还没等我高兴,便看到了:
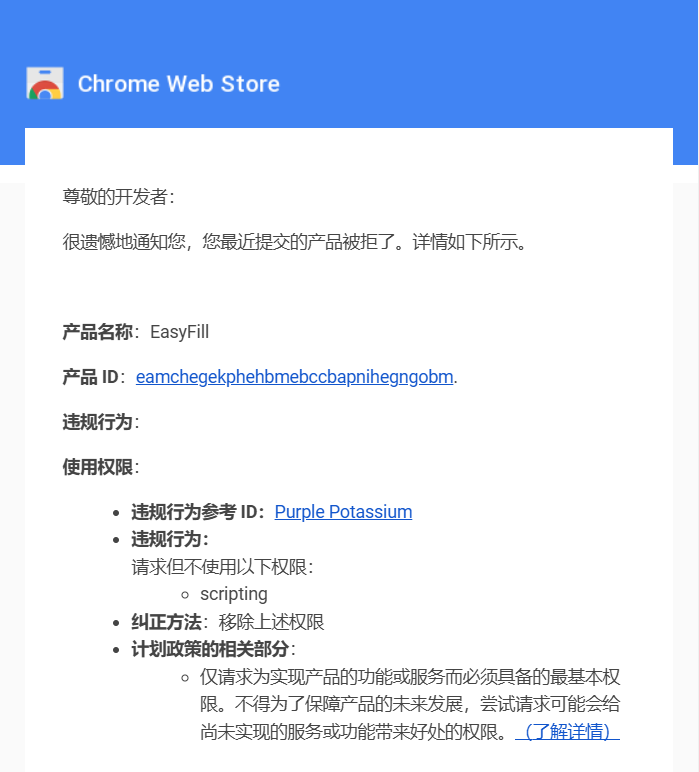
被拒的原因非常低级,声明了但未使用的 scripting 权限。
scripting 权限是 Manifest V3 中引入的一个重要权限,主要用于动态脚本执行chrome.scripting.executeScript()和动态样式注入chrome.scripting.insertCSS()
而在EasyFill中,使用的是静态声明:
content_scripts: [
{
matches: ['<all_urls>'],
js: ['content-scripts/content.js']
}
]
删除scripting参数后,重新打包并再次向 Chrome Web Store 提交了扩展。
就这么一个小BUG,浪费了我一个星期的审核时间,太耽误事了,当时为了解决 Shadow DOM 才使用 scripting,直到现在这个问题也没有解决,希望下个版本可以解决问题
产品谍照:
4月2,三月初五,周三。
和小汪初次相遇是在单位楼下,看着她从大门迎着九点钟的朝阳小跑过来,我已经心动了。从小电驴里把两盒蓝莓递给她时,装作漫不经心很随意的我双手都有些紧张得微微颤抖。
来的路上还是有点小插曲。本打算搞盒草莓尝尝,还要去零食店准备能量补品士力架,所以来的路上紧赶慢赶——经常被鹏董和纪公子批评说是出门就要蹲半小时厕所的我想着这次可得早到。结果到了两家水果店都因为太早而还没到新鲜草莓的货,只好换吃蓝莓,味道还真不错。之后就是熟悉的捡垃圾!难得遇见一位好同志愿意陪我爬山做公益。感受:好久没运动,够呛哈哈。中午吃炸鸡补充能量,下午一起去新华书店看中国地图=o=
中午两点时还请小汪陪我去趟相馆拍了张最新照片,去年也是在这一家拍的。因为我当时各类场合用的仍然还是一八年高考后的证件照,过六年了都,不能再掏出来装嫩了。今年去之前给老板发了个消息问在不在,他应该也是看见了去年聊天记录,所以我到了前台说要拍证件照后,第一句就问我说不是刚拍过了嘛。我答曰:今后每年都要更新一次。
之后的发展,就是拉着小乖陪我一起散步、一起逛街,摸黑逛公园,探索新食物,还有鄱阳湖边吹凉风……我想起了近二十年前的某天晚上,和爹娘一同在发小家里聊天玩耍,有一刹那我恍惚间感觉就像身处梦幻,周边一切都太安宁太惬意了,那个氛围至今也不能忘。有时和小乖在一起,我也会恍惚感觉好幸福呀。想起以前有一天我愣是在美梦里笑醒了,但是现在,我能紧紧握住身旁小汪的手掌心,我能把她拥入我怀中~这是来自小乖的、独属于我的真切情意。

在网站开发领域,为用户提供高效便捷的内容订阅途径,是提升用户体验、增强用户粘性的关键举措。在使用Z-BlogPHP搭建网站时,我们能够借助自定义PHP脚本,打造满足特定需求的Feed输出功能。接下来,本文将深入剖析feed_id.php和page_feed.php这两个脚本的功能、实现逻辑,以及基于它们所创建的 “订阅” 栏目。
feed_id.php脚本主要用于依据Z-BlogPHP中的分类$categoryId,展示对应分类下的部分内容,生成分类的Feed输出。该脚本首先引入Z-BlogPHP系统核心文件并加载系统,为后续操作奠定基础。接着从URL参数获取分类ID,对其进行有效性验证,若分类ID无效或对应分类不存在,则输出错误信息并终止脚本运行。之后设置响应头为XML格式,生成XML声明及RSS 2.0文档的相关结构,并填充频道的标题(含分类名称和博客名称)、链接(分类链接)、描述(分类简介)和语言等信息。最后通过 $zbp->GetArticleList() 方法获取指定分类下正常发布的文章列表,按发布时间倒序排列,循环输出最多10篇文章的标题、链接、描述、发布日期和唯一标识符等内容,完成 Feed 的生成。比如,访问下方URL就能获取分类ID为2的分类内容的Feed输出。
https://www.dao.js.cn/feed_id.php?id=2
page_feed.php 脚本的核心功能是通过 GetPageList 方法获取网站内所有单页的信息,并生成相应的 Feed 输出。此脚本同样先引入并加载Z-BlogPHP系统,将当前操作类型设为feed并设置XML格式的响应头。然后执行相关钩子函数,生成XML声明和RSS 2.0文档的起始结构,填充频道的标题(含 “所有单页” 和博客名称)、链接(博客主页链接)、描述(所有单页的 RSS Feed)及语言等信息。再利用$zbp->GetPageList()方法获取所有单页列表,循环输出每个页面的标题、链接、描述(页面简介)、发布日期和唯一标识符等信息,最后结束XML结构并执行相应钩子函数。用户通过访问下方URL,便能获取所有的Feed输出。
https://www.dao.js.cn/page_feed.php
在完成feed_id.php和page_feed.php脚本的编写后,我们进一步创建了 “订阅” 栏目。用户访问 https://www.dao.js.cn/feed 即可进入该栏目,在此查看不同分类的内容Feed以及所有单页的Feed,及时掌握网站的最新动态。
通过对feed_id.php和page_feed.php脚本的精心开发与应用,我们在Z-BlogPHP网站中成功实现了自定义 Feed 输出功能,并搭建起 “订阅” 栏目。这不仅优化了网站的内容展示效果,还为用户提供了更为便捷的内容获取方式,有助于提升用户的留存率与活跃度。在今后的网站开发和维护中,我们还可依据实际需求,对这些脚本进行优化和拓展,以适应不断变化的业务场景。
需要feed_id.php和page_feed.php文件的,请通过“联系”栏目与我取得联系。feed页面模板如下:
<h2>总体订阅</h2>
<div class="category-wrapper">
<a target="_blank" href="/feed.php" class="dingyue" title="南蛮子懋和博客默认订阅">
<div class="dingyuetext">
<div class="dingyuexl">默认订阅</div>
</div>
<i class="bi bi-rss"></i>
</a>
<a target="_blank" href="/page_feed.php" class="dingyue" title="南蛮子懋和博客单页订阅">
<div class="dingyuetext">
<div class="dingyuexl">单页订阅</div>
</div>
<i class="bi bi-rss"></i>
</a>
</div>
<h2>分类订阅</h2>
<div class="category-wrapper">
{php}
global $zbp;
$categories = $zbp->GetCategoryList();
foreach ($categories as $category) {
if ($category->ID != 1) {
$feed_url = 'feed_id.php?id='.$category->ID;
{/php}
<a target="_blank" href="{php}echo $feed_url;{/php}" class="dingyue" title="{php}echo $category->Intro;{/php}">
<div class="dingyuetext">
<div class="dingyuexl">{php}echo $category->Name;{/php}</div>
</div>
<i class="bi bi-rss"></i>
</a>
{php}
}
}
{/php}
</div>依照Z-BlogPHP创建自定义页面方式,再合适的地方插入即可。需要feed样式的,可以自行f12复制,也可以向我索取,具体展示渲染效果如下:
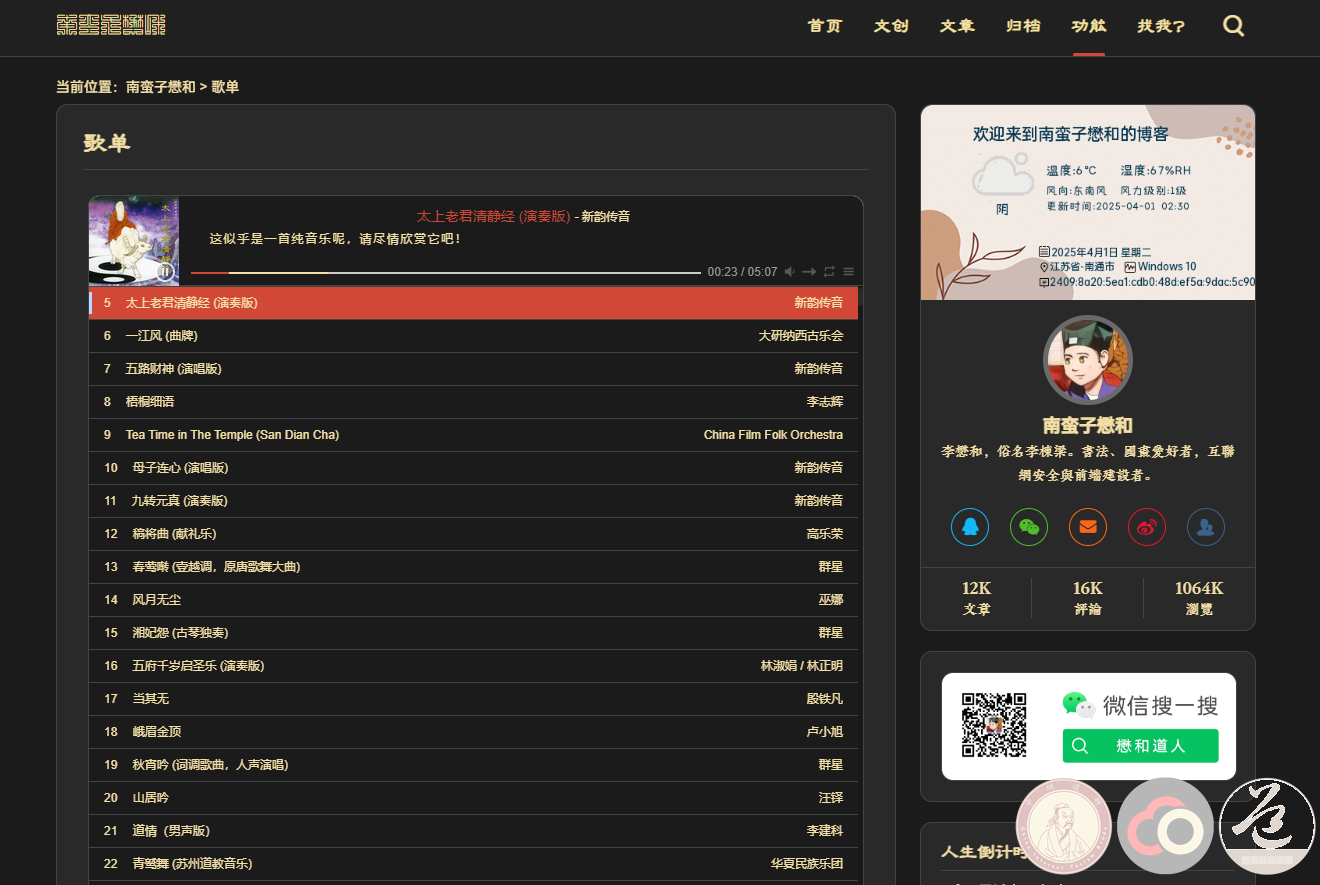
在音乐爱好者的世界里,拥有一个能自由听取的个性化歌单是许多人的梦想。为了实现这一目标,我借鉴了张洪 HeoMusic 的思路,成功搭建了属于自己的歌单页面。
https://blog.zhheo.com/p/45699256.html
张洪 HeoMusic 的思路为整个项目提供了关键的指引方向,其独特的架构理念和对音乐播放系统的理解,成为我搭建歌单页面的基石。在这个基础上,我对Meting.min.js进行了二次更改,这一举措极大地拓展了音乐获取的自由度。通过对代码的精细调整,我可以更灵活地从不同渠道获取心仪的音乐,让歌单内容更加丰富多样。值得注意的是因为跨域等问题,我们需要自己构建、或者反代一个API,因为版权原因,暂不提供思路,我是使用的injahow/meting-api使用cloudflare搭建的API。
为了实现多id合并并打乱顺序输出json,我对Meting.min.js进行了下述修改(尊重著作权,console.log输出版权信息)
class MetingJSElement extends HTMLElement {
constructor() {
super();
this._initialized = false;
}
connectedCallback() {
if (window.APlayer && window.fetch &&!this._initialized) {
this._init();
this._parse();
this._initialized = true;
}
}
disconnectedCallback() {
if (!this.lock && this.aplayer) {
this.aplayer.destroy();
}
}
_camelize(str) {
return str
.replace(/^[_.\- ]+/, '')
.toLowerCase()
.replace(/[_.\- ]+(\w|$)/g, (m, p1) => p1.toUpperCase());
}
_init() {
let config = {};
for (let i = 0; i < this.attributes.length; i += 1) {
config[this._camelize(this.attributes[i].name)] = this.attributes[i].value;
}
let keys = [
'server', 'type', 'id', 'api', 'auth',
'auto', 'lock',
'name', 'title', 'artist', 'author', 'url', 'cover', 'pic', 'lyric', 'lrc',
];
this.meta = {};
for (let key of keys) {
this.meta[key] = config[key];
delete config[key];
}
this.config = config;
this.api = this.meta.api || window.meting_api || 'https://xxx.xxx.xxx/?server=:server&type=:type&id=:id&r=:r';
if (this.meta.auto) this._parse_link();
// 支持多个 ID,将 id 属性按逗号分割成数组
this.meta.ids = this.meta.id.split(',');
}
_parse_link() {
let rules = [
['music.163.com.*song.*id=(\\d+)', 'netease', 'song'],
['music.163.com.*album.*id=(\\d+)', 'netease', 'album'],
['music.163.com.*artist.*id=(\\d+)', 'netease', 'artist'],
['music.163.com.*playlist.*id=(\\d+)', 'netease', 'playlist'],
['music.163.com.*discover/toplist.*id=(\\d+)', 'netease', 'playlist'],
['y.qq.com.*song/(\\w+).html', 'tencent', 'song'],
['y.qq.com.*album/(\\w+).html', 'tencent', 'album'],
['y.qq.com.*singer/(\\w+).html', 'tencent', 'artist'],
['y.qq.com.*playsquare/(\\w+).html', 'tencent', 'playlist'],
['y.qq.com.*playlist/(\\w+).html', 'tencent', 'playlist'],
['xiami.com.*song/(\\w+)', 'xiami', 'song'],
['xiami.com.*album/(\\w+)', 'xiami', 'album'],
['xiami.com.*artist/(\\w+)', 'xiami', 'artist'],
['xiami.com.*collect/(\\w+)', 'xiami', 'playlist'],
];
for (let rule of rules) {
let patt = new RegExp(rule[0]);
let res = patt.exec(this.meta.auto);
if (res!== null) {
this.meta.server = rule[1];
this.meta.type = rule[2];
this.meta.id = res[1];
return;
}
}
}
async _parse() {
if (this.meta.url) {
let result = {
name: this.meta.name || this.meta.title || 'Audio name',
artist: this.meta.artist || this.meta.author || 'Audio artist',
url: this.meta.url,
cover: this.meta.cover || this.meta.pic,
lrc: this.meta.lrc || this.meta.lyric || '',
type: this.meta.type || 'auto',
};
if (!result.lrc) {
this.meta.lrcType = 0;
}
if (this.innerText) {
result.lrc = this.innerText;
this.meta.lrcType = 2;
}
this._loadPlayer([result]);
return;
}
const allMusicData = [];
for (const id of this.meta.ids) {
let url = this.api
.replace(':server', this.meta.server)
.replace(':type', this.meta.type)
.replace(':id', id)
.replace(':auth', this.meta.auth)
.replace(':r', Math.random());
try {
const res = await fetch(url);
if (!res.ok) {
throw new Error(`HTTP error! status: ${res.status}`);
}
const text = await res.text();
const result = JSON.parse(text);
if (Array.isArray(result)) {
allMusicData.push(...result);
} else {
console.error(`Data for ID ${id} is not an array:`, result);
}
} catch (error) {
console.error(`Fetch error for ID ${id}:`, error);
}
}
// 对获取到的所有音乐数据进行随机排序
const shuffledMusicData = this._shuffleArray(allMusicData);
this._loadPlayer(shuffledMusicData);
}
_shuffleArray(array) {
for (let i = array.length - 1; i > 0; i--) {
const j = Math.floor(Math.random() * (i + 1));
[array[i], array[j]] = [array[j], array[i]];
}
return array;
}
_loadPlayer(data) {
let defaultOption = {
audio: data,
mutex: true,
lrcType: this.meta.lrcType || 3,
storageName: 'metingjs'
};
if (!data.length) return;
let options = {
...defaultOption,
...this.config,
};
for (let optkey in options) {
if (options[optkey] === 'true' || options[optkey] === 'false') {
options[optkey] = (options[optkey] === 'true');
}
}
let div = document.createElement('div');
options.container = div;
this.appendChild(div);
this.aplayer = new APlayer(options);
}
}
console.log('\n %c MetingJS v2.0.1 %c https://github.com/metowolf/MetingJS \n', 'color: #fadfa3; background: #030307; padding:5px 0;', 'background: #fadfa3; padding:5px 0;');
if (window.customElements &&!window.customElements.get('meting-js')) {
window.MetingJSElement = MetingJSElement;
window.customElements.define('meting-js', MetingJSElement);
}然而,在享受技术带来的便利时,我们绝不能忽视著作权的重要性。每一首音乐都是创作者的心血结晶,我们应当在合法合规的前提下使用这些作品,确保对知识产权的尊重。
在前端渲染方面,我选择了APlayer播放器。APlayer以其简洁美观的界面和强大的功能,为用户带来了优质的播放体验。它能够流畅地展示歌曲信息、控制播放进度,并且支持多种主题自定义,使歌单页面在功能性和美观性上达到了较好的平衡。
在前端仅需要随便往哪里插入下列代码即可(我是获取的“我收藏的歌单”下列的歌单,id是什么,需要自行理解,我尊重各站版权)
<link rel="stylesheet" href="/sucai/APlayer/APlayer.min.css"> <script src="/sucai/APlayer/APlayer.min.js"></script> <script src="/sucai/APlayer/Meting.min.js"></script> <meting-js server="netease" type="playlist" id="6948853317,326934130,446132364,978446985,2286543721,7235859079" autoplay="true" order="list" preload="auto" list-max-height="100vh"></meting-js>
通过这次实践,我不仅实现了歌单听取自由化的目标,还在技术运用和版权意识上有了更深的体会。希望我的经验能为其他音乐爱好者和开发者提供一些参考,共同打造更加优质、合法的音乐环境。
在日常维护网站的过程中,一个细节问题引起了我的注意。一直以来,我都十分珍视与其他站点的友好合作关系,通过友情链接、联盟推广等方式,努力为用户拓展更多优质的信息渠道。然而,近期我在对网站进行深入检查时发现,博客中许多站外跳转链接,包括友链等,都没有正确设置 rel 标签。其实,由于一些不可控因素,之前我为所有站外跳转链接设置了中间跳转机制,本意是为了更好地管理和保障用户的浏览安全。但在这个过程中,却疏忽了 rel 标签的设置。
https://www.dao.js.cn/new/2025030511627.shtml
经过对友链的逐一排查,我发现目前共有 58 个友链站点。其中 41 个站点对出站链接(不限于友链)的 a 标签设置了 rel="noopener noreferrer nofollow",这体现了他们对网站 SEO 优化和链接管理的重视。有 5 个站点采用了转译的 golink 跳转方式处理出站链接,而 “爱写书” 站点则完全没有设置 target 和 rel 标签。其余站点虽设置了 target 跳转,但 rel 标签方面存在缺失。
对于友情链接设置 rel 标签,我内心一直有所顾虑。毕竟友情链接是网站之间友好交流的桥梁,设置 rel="noopener noreferrer nofollow" 可能会在一定程度上影响到友链站点的权益,感觉对友链朋友不够友好。尤其是 “爱写书” 站点,没有对我的站点链接做过多限制,这种信任让我很是感激。但从网站自身的 SEO 角度出发,缺失 rel 标签可能会导致 SEO 权重外流,影响网站在搜索引擎中的表现。
在这种纠结的心态下,我经过反复思考,最终决定还是要对网站的外链进行合理处理,以平衡网站自身发展和与友站的关系。
从 SEO 的专业知识来讲,rel 标签的正确设置对于网站的权重分配和安全性至关重要。rel="noopener noreferrer nofollow" 这组属性,一方面可以有效防止搜索引擎将本站权重过多传递到外部链接,保障自身网站在搜索排名中的优势;另一方面,也能避免用户因误点恶意外链而带来的潜在风险。
然而,在实际操作中,要对全站的外链进行统一处理并非易事。网站的外链数量众多,来源复杂,涵盖了友链、广告链接、合作推广链接等多种类型。不同类型的外链,其功能和目的各异,处理方式也不能一概而论。而且,在处理外链时,还必须充分考虑用户体验。如果处理不当,可能会导致部分链接无法正常跳转,或者给用户的浏览过程带来不必要的困扰。经过慎重考虑,我认为对全站非 window.location.hostname 的 a 标签 url 施行强制 rel="noopener noreferrer nofollow" 处理是较为合适的方案。
这样既能最大程度地保障网站的 SEO 效果,又不会对用户的正常浏览造成严重影响。对于站内链接,用户可以自由访问;而对于站外链接,设置 rel 标签则是在保护网站自身利益的同时,也提醒用户谨慎对待外部链接。
为了实现对全站外链的自动化处理,我借助了 JavaScript 技术。以下是具体的代码实现:
document.addEventListener('DOMContentLoaded', function () {
const currentDomain = window.location.hostname;
// 处理所有现有的 <a> 标签
const allLinks = document.getElementsByTagName('a');
for (let i = 0; i < allLinks.length; i++) {
const link = allLinks[i];
const href = link.href.trim();
if (isValidExternalLink(href, currentDomain)) {
link.setAttribute('rel', 'noopener noreferrer nofollow');
}
}
// 创建一个 MutationObserver 实例来监听 DOM 变化
const observer = new MutationObserver((mutationsList) => {
for (const mutation of mutationsList) {
if (mutation.type === 'childList') {
// 遍历新增的节点
for (const addedNode of mutation.addedNodes) {
if (addedNode.nodeName === 'A') {
const link = addedNode;
const href = link.href.trim();
if (isValidExternalLink(href, currentDomain)) {
link.setAttribute('rel', 'noopener noreferrer nofollow');
}
} else if (addedNode.querySelectorAll) {
// 检查新增节点的子节点中是否有 <a> 标签
const newLinks = addedNode.querySelectorAll('a');
for (const newLink of newLinks) {
const href = newLink.href.trim();
if (isValidExternalLink(href, currentDomain)) {
newLink.setAttribute('rel', 'noopener noreferrer nofollow');
}
}
}
}
} else if (mutation.type === 'attributes' && mutation.attributeName === 'href') {
const link = mutation.target;
const href = link.href.trim();
if (isValidExternalLink(href, currentDomain)) {
link.setAttribute('rel', 'noopener noreferrer nofollow');
}
}
}
});
// 配置 MutationObserver 监听的选项
const config = { childList: true, subtree: true, attributes: true, attributeFilter: ['href'] };
// 开始监听 document.body 及其子节点的变化
observer.observe(document.body, config);
function isValidExternalLink(href, currentDomain) {
if (!href || href.startsWith('#') || href.startsWith('javascript:')) {
return false;
}
try {
const url = new URL(href);
return url.hostname!== currentDomain;
} catch (error) {
return false;
}
}
});这段代码的逻辑是:当页面加载完成(DOMContentLoaded 事件触发)时,获取当前页面的域名 currentDomain。然后遍历页面上所有的 <a> 标签,获取每个标签的 href 属性并进行修剪。通过 isValidExternalLink 函数判断该链接是否为有效的外部链接,如果是,则为其添加 rel="noopener noreferrer nofollow" 属性。同时,利用 MutationObserver 监听 DOM 的变化。当检测到有新节点添加(childList 类型变化)或 <a> 标签的 href 属性改变(attributes 类型变化且 attributeName 为 href)时,对新的或属性变化的 <a> 标签执行相同的检查和处理操作。
在代码编写完成后,我进行了严格的测试。先在本地开发环境中模拟各种页面情况和外链类型,确保代码能准确识别和处理外部链接。随后在生产环境中选取部分页面进行试点,观察实际运行效果并及时调整,最终保证代码能够稳定、有效地运行。
经过对全站外链的处理,取得了较为显著的效果。从 SEO 方面来看,正确设置 rel 标签后,有效避免了 SEO 权重外流的问题。之前由于很多外链未设置 rel 标签,搜索引擎在抓取页面时可能会将部分权重传递到外部,影响网站自身排名。现在,搜索引擎能够更准确地处理外链,将权重更多地集中在站内页面,有助于提升网站在搜索结果中的整体排名。
在用户体验方面,虽然对外部链接设置了 rel 标签,但由于处理方式合理,并未对用户的正常浏览和跳转造成明显阻碍。用户依然可以自由点击外部链接,同时也在一定程度上提高了浏览的安全性,减少了恶意链接带来的潜在风险。此外,通过这次对外链的全面梳理和处理,我对网站的链接结构有了更清晰的认识。发现并清理了一些无效链接和重复链接,进一步优化了网站的性能和稳定性,为用户提供了更优质的浏览体验。
当然,SEO 优化是一个持续的过程,外链处理只是其中的一部分。未来,我会继续关注网站的 SEO 效果,不断优化和调整策略。同时,也会更加注重与友链站点的沟通与合作,在保障自身网站发展的前提下,维护好与友站的友好关系,共同促进互联网生态的健康发展。
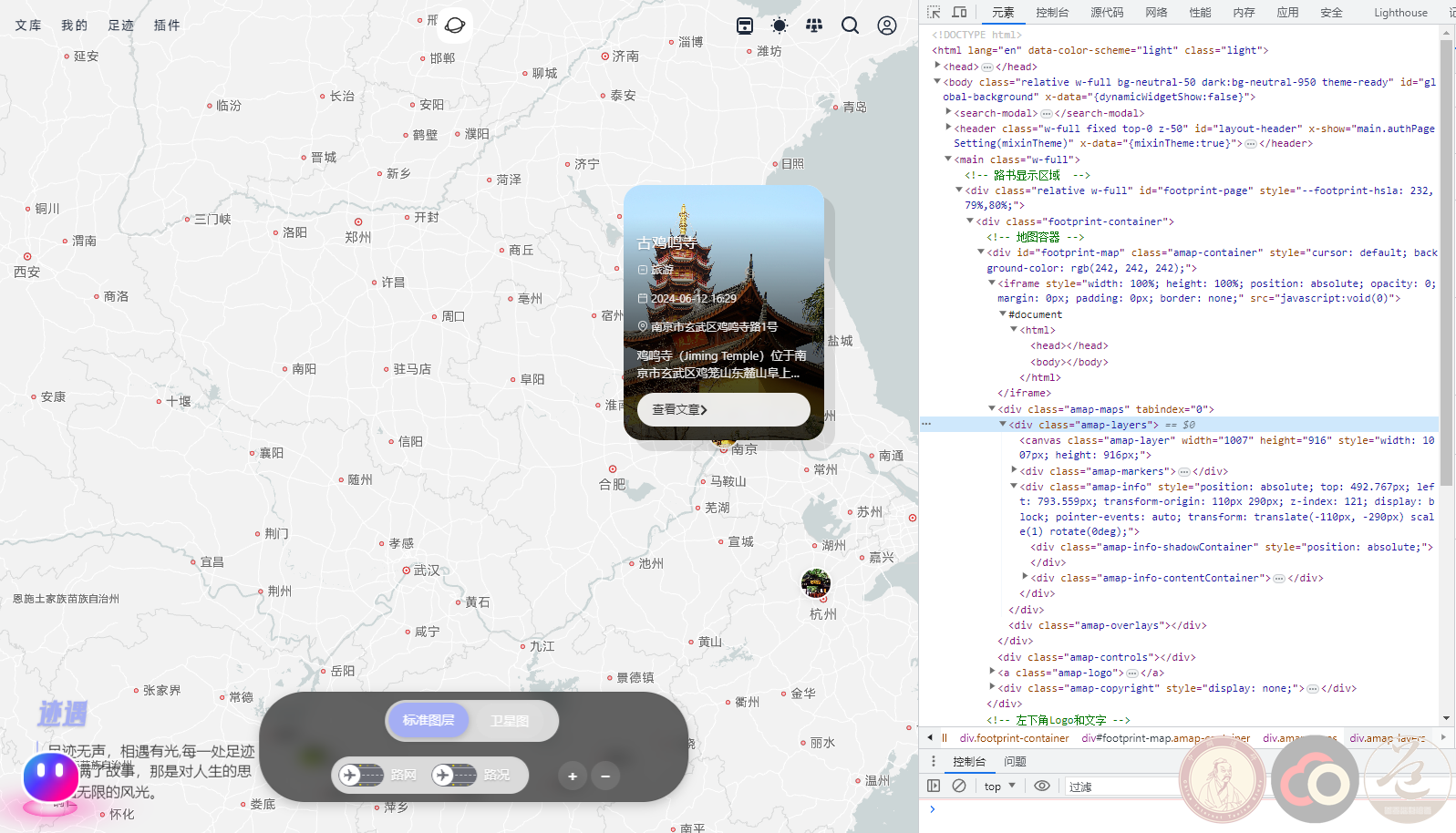
最近我被 “足迹” 功能深深吸引住了,起因是逛了好多博客,发现人家都有这么个有意思的功能,能在地图上标记去过的地方,分享自己的旅程。这可把我馋坏了,心心念念着自己的博客也得安排上。为这事儿,我晚上翻来覆去,脑子里全是怎么实现 “足迹” 功能,根本睡不着觉,辗转反侧、寤寐思服、夜不能寐,满心满眼就只有这一件事。
今天总算是下定决心开始动手了,找来找去,发现泽泽社长的 NiceMapMarker 插件简直就是为我量身定制的!它能基于腾讯地图 API 和百度地图 API 实现地图多地点标记,这不就是我一直想要的嘛!
https://store.typecho.work/archives/NiceMapMarker-typecho-plugin.html
我赶紧打开插件介绍页面,仔仔细细研究起来。这一看,发现使用前准备工作还不少。首先得去腾讯地图开放平台和百度地图开放平台申请开发者账号。腾讯那边登录账号新建应用,选浏览器端,建好后能拿到应用 key;百度这边类似,新建应用拿到 AK,然后都填到插件设置里。这一步虽说有点繁琐,但难不倒我,按部就班地操作,很快就搞定了。
接着就是查经纬度,用哪个平台就在哪个平台查。腾讯地图在指定的网址查,百度地图也有对应的查询页面。我一边查,一边感慨这细节还挺多,不过每完成一步,离实现 “足迹” 功能就更近一步,心里那叫一个兴奋。
设置参数的时候也有点小挑战。它可以用zoom参数设置地图缩放,默认是 5,还能用height参数设置地图组件在文章里显示的高度。一开始,我设置的参数没达到预期效果,地图不是缩放得不合适,就是显示高度不对。好在我多试了几次,不断调整,总算是让地图显示得像模像样了。
在文章里按照格式书写标记信息的时候,我又遇到了点小麻烦。超链接和图片链接的填写得格外注意,有一次因为少写了个符号,怎么都显示不对。不过,经过反复检查和修改,最终还是成功实现了!看着地图上一个个标记着我 “足迹” 的点,心里别提多有成就感了。
现在,我的博客 “足迹” 功能算是初步完成了。虽然过程中遇到了不少问题,但好在都一一解决了。接下来,我打算再优化优化,比如多找些好看的图片当标记,让 “足迹” 页面更美观。今天的成果让我对后续的开发充满了信心,期待能给博客带来更多有趣的功能!