GTK应用开发小记
夏季学期课程的小组作业,是要开发一个基于Linux内核模块的包过滤防火墙。主要有两部分的任务:
配置程序
运行在应用层,用来配置过滤规则,包括协议类型、IP地址、端口号、开始和结束时间、是否启用规则等。
Linux内核模块
运行在内核层,完成包过滤防火墙的功能,该模块借助注册Netfilter钩子函数的方式来实现对数据包的过滤和控制。
我主要负责了第一部分的任务:开发一个友好的包过滤规则的配置和管理界面(GUI部分,CLI部分由组里另一位同学负责)。支持包过滤的规则导入、导出,添加、编辑、 删除、搜索等功能。应用界面如下:
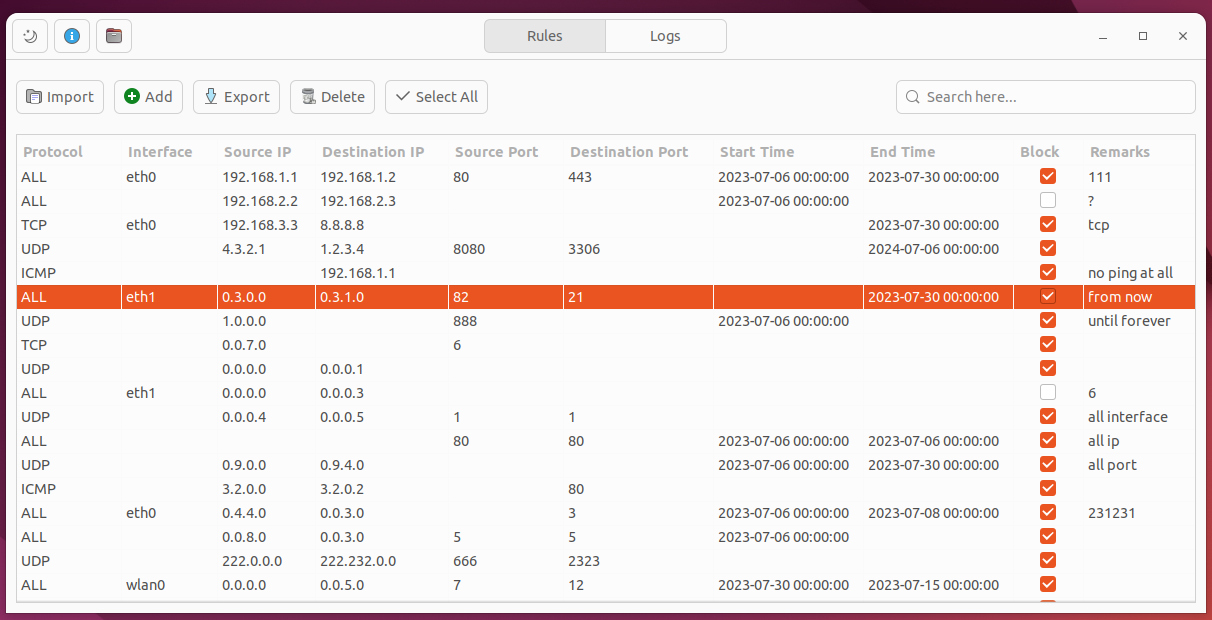
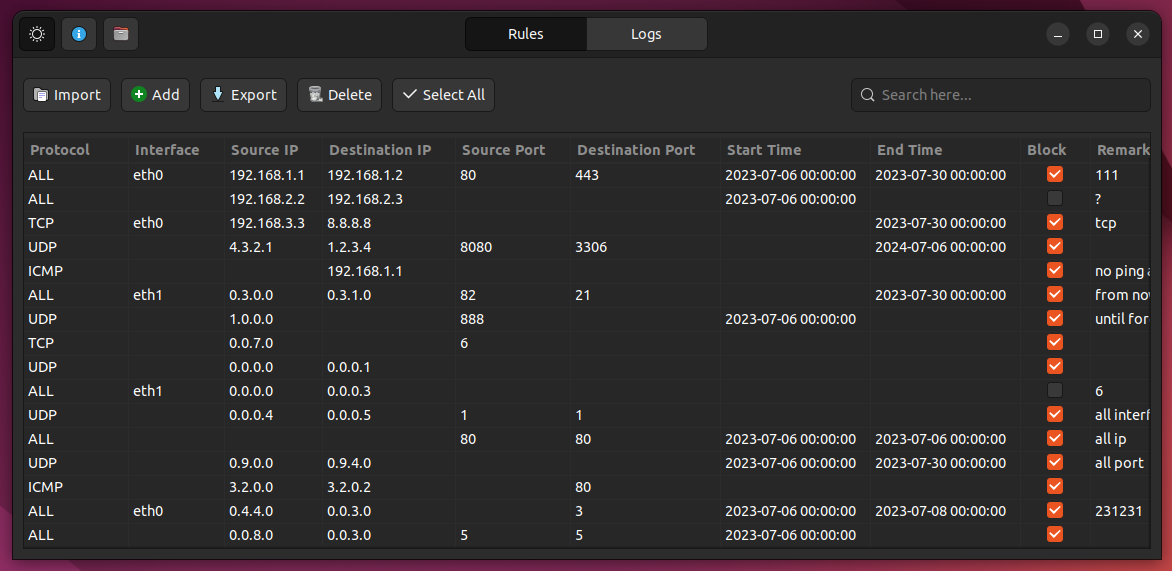
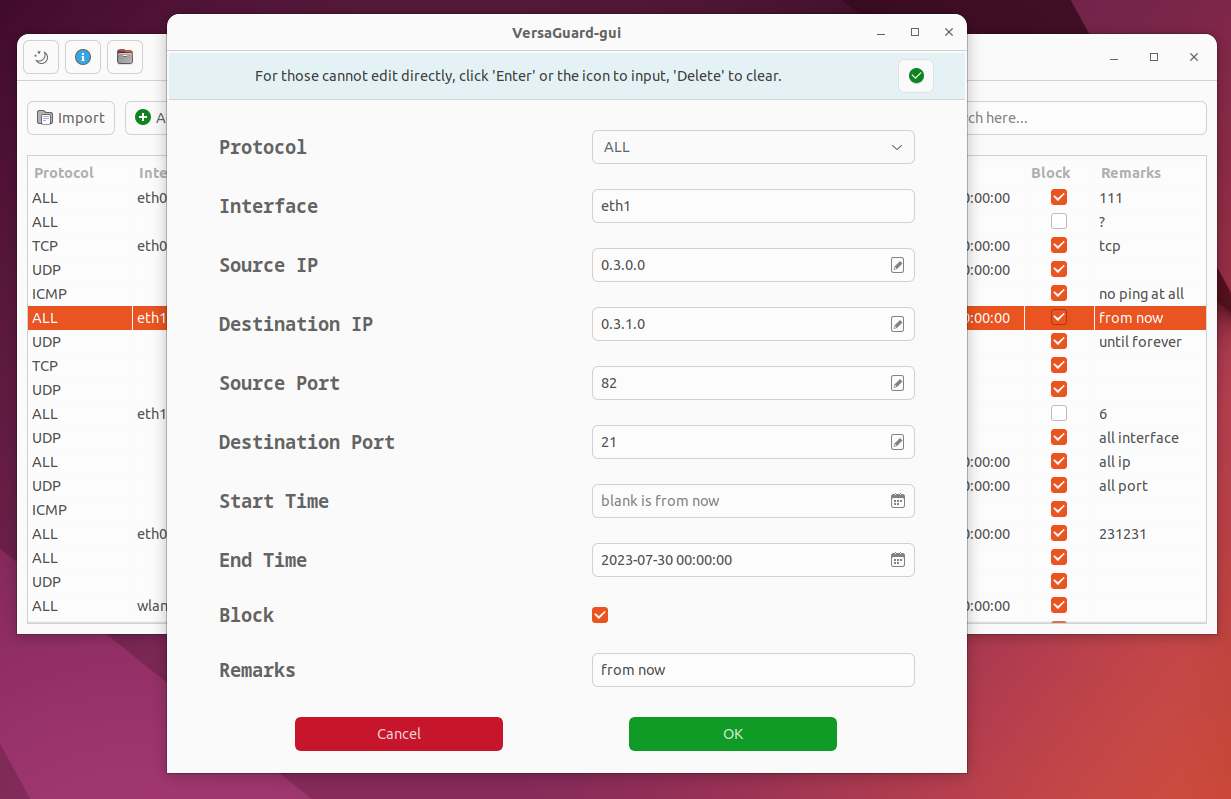
谈不上好看,但也不至于很丑。
GTK vs QT
GTK和QT是非常有名的两个GUI库,当然QT应该是更有名些。GTK和QT的优势对比如下:
- QT:
- 跨平台性:QT是一个跨平台的工具包,可以在多个操作系统上运行,包括Windows、Linux、macOS等。它提供了一致的API,使得开发者可以轻松地编写一次代码,然后在不同的平台上进行部署和运行。
- 高度集成:QT提供了丰富的组件和工具,涵盖了广泛的应用开发需求,包括图形渲染、网络通信、数据库访问等。它还提供了开发者友好的IDE和调试工具,使得开发过程更加高效。
- QML和Qt Quick:QT引入了QML和Qt Quick技术,允许开发者使用声明性语言和组件化的方式来设计和构建用户界面。这种方式简化了UI设计和开发的过程,并提供了良好的可扩展性。
- 商业支持:QT由The Qt Company开发和维护,提供了商业许可和支持服务。这对于企业级应用开发来说是一个优势,因为他们可以获得专业的技术支持和保障。
- GTK:
- 开源性:GTK是一个开源工具包,它的代码可以被自由地查看、修改和分发。这对于开源社区和个人开发者来说是一个优势,他们可以根据自己的需求进行自定义和改进。
- UNIX哲学:GTK是基于UNIX哲学设计的,它鼓励模块化和简洁的设计。这种设计理念使得GTK在Linux等UNIX-like系统上有着很好的集成和兼容性。
- GNOME集成:GTK是GNOME桌面环境的默认工具包,它与GNOME的集成非常紧密。如果你计划开发适用于GNOME桌面环境的应用程序,使用GTK可能更加方便和自然。
- 多语言支持:GTK支持多种编程语言,包括C、C++、Python等。这使得开发者可以使用自己喜欢的编程语言来进行应用程序的开发。
最终我是选择了GTK3进行GUI开发,原因如下:
- 这次开发的防火墙程序是基于Linux内核模块的,所以只能在Linux系统使用,不需要考虑GUI的跨平台。
- Glade应用提供了GTK应用的UI设计功能,起到和QML、Qt Quick类似的作用。
- 开源、不需要商业支持。
- 防火墙属于网络层的应用,不需要太多功能,简洁至上。
- 在Ubuntu22.04环境下开发,使用GTK接近原生UI。
- GTK的默认样式足够好看。
GTK & glade学习
GTK相比QT的一个最大劣势就是文档更少、社区也更不活跃。B站和YouTube搜索QT,有非常多的教程,而GTK相对来说就比较少了。另外GTK4已经问世数年,但是教程大多还是GTK3。之前提到用来设计GTK应用UI的glade,支持的最高GTK版本也是GTK3。
好在对于这样一个简单的GUI应用,只需要入门GTK便可。学习一样工具,我总是喜欢边学边做。因此视频+文档的组合往往是更适合我的。在我学习GTK开发的过程中,主要参考了以下资源:
YouTube上的GTK & glade开发教程,没有涵盖GTK的所有类,但对入门来说够用而且友好。
更多时候我其实是直接看源代码学习,视频节奏有些拖沓,一旦理解GTK和glade是怎样工作的,看代码会是更高效的解决方法。
文档很全面,但只有英文。
ChatGPT
文档没写全的、视频没讲到的可以问问GPT。看看思路可以,3.5写出来的代码可能不能直接用。
GTK & glade开发流程
使用GTK & glade开发,主要是应用UI设计和功能实现分离的思想。
在glade应用中设计UI
哪里是按钮,哪里需要输入框,哪里需要列表等等,需要提前构思好。
在glade应用中连接信号(signals)
所谓信号,就是当用户与界面发生某种特定的交互时,应用程序便会知悉,并可根据这种信号回调对应的函数、传入特定的数据进行特定的操作。可以在glade中连接信号并指定对应的回调函数,以及需要传入的数据。这样在后续功能实现时,只需将这些函数的功能实现即可,也很好地实现了模块化。
编写GTK代码
主要是实现之前在glade中指定的回调函数。另外,一些用于提示用户的对话框也可以直接用代码生成。
编译程序
在开发阶段,一般从glade文件加载builder(gtk_builder_new_from_file),并使用
gcc的-export-dynamic参数。这样一来,修改glade文件后无需重新编译就可以看到新的UI。而在生产环境中,不能使用上述方法。因为上述方法编译的应用程序需要依赖glade文件运行,而一般用于生产环境的应用程序需要将glade文件一同编译成最后的二进制程序。因此要从资源中加载builder(gtk_builder_new_from_resource)。因此首先要把glade文件编译成资源,这个过程需要用到
glib-compile-resources工具。具体方法可以参照Linux Gtk Glade Programming Part 34: Embedding resources in your app。
难点
TreeView
GTK中的TreeView以及ListBox是非常重要的组件,适合用于用户与系统的数据交互,区别在于TreeView可以有多层父子结构,而ListBox只有单层。
Log功能
Log功能的第一版思想是:每隔一段时间(如1s)监测日志文件的变化,当日志文件大小发生改变时,将新增的内容显示在应用的TextView当中。但是如果使用一个线程,会导致应用要轮流处理与用户的交互和日志文件的监测,而日志文件又需要频繁监测,造成较差的用户体验。因此为监测日志文件变化的功能单独创建一个线程进行处理。
但是线程需要应对一系列互斥与共享的问题,因此我换了一种实现方法。
第二版的思想是:使用
GFileMonitor来监测文件的变化,当文件变化时,会发出一个信号,GTK应用能捕捉这个信号并做出相应的处理。GFileMonitorVS 多线程:优点:
- GFileMonitor使用更简单,不需要自己编写多线程逻辑。它提供了文件变化事件的回调接口,只需要关心事件处理逻辑。
- GFileMonitor对文件系统事件的处理可能更高效。它基于操作系统提供的文件变化监控机制,不需要频繁地轮询检查文件。
- GFileMonitor可以方便地跨平台使用,而自行实现的多线程文件监视可能需要针对不同平台调整。
缺点:
- GFileMonitor的可定制性较低,不能自由控制轮询频率等参数。
- GFileMonitor可能不支持监视网络文件系统或一些特殊文件系统。
- GFileMonitor基于系统调用,系统开销可能略大于纯用户态的多线程实现。
- 自行实现的多线程方案可以加入更多自定义逻辑,例如合并事件、缓存等。