Chsrc--全功能一键换源工具
详细介绍了chsrc工具的安装和使用,提供了简单的命令帮助开发者快速切换不同语言的源,提升开发效率。无论是熟练用户还是新手,chsrc都能让换源变得简单高效,解决了换源过程中的一些困扰。
梦开始的比赛。去年纯小白直接参赛,结果自然是被血虐。之后开始慢慢学,今年总算是做出些题。不过难一些的 PWN 题还是做不出……( ),就多练。
签到题。
浏览器安装一个 MetaMask 钱包用于区块链操作。连接钱包后答题,收集任意7个不同食材图片后,点击兑换 NFT ,得到含 flag 的图片:
得到 flag :
1 | flag{y0u_ar3_hotpot_K1ng} |
这是一道基于功耗分析的侧信道攻击题,搜索相关关键词,在看雪上找到一篇文章。根据文章内容可知,输入密码逐位比对,输入正确时和错误时功耗曲线有明显不同。
将得到的 npz 加载后打印数据,发现一共有13*40组数据,40对应着40个字符,猜测13为密码位数。打印所有功耗曲线,可以发现: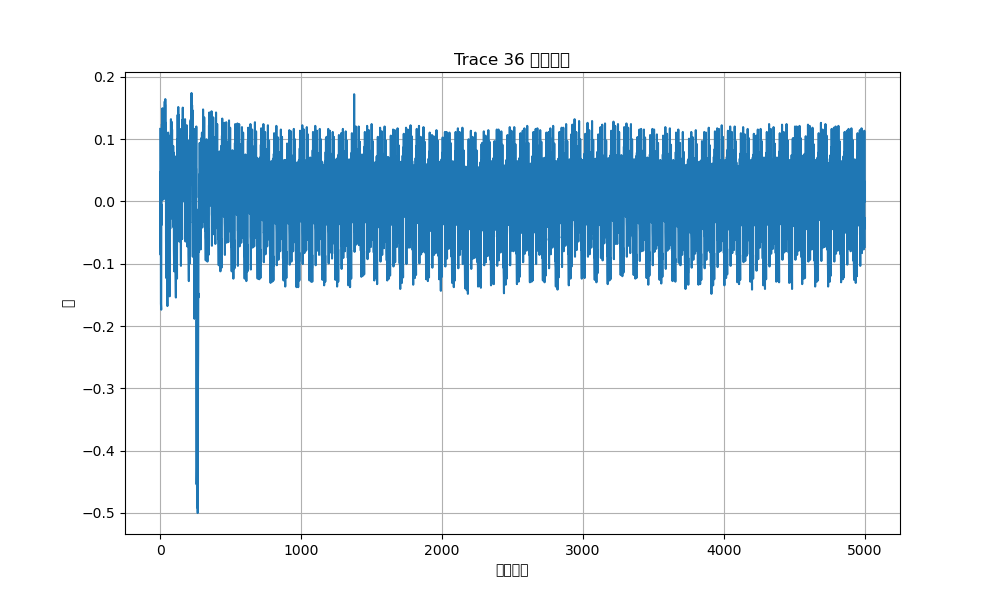
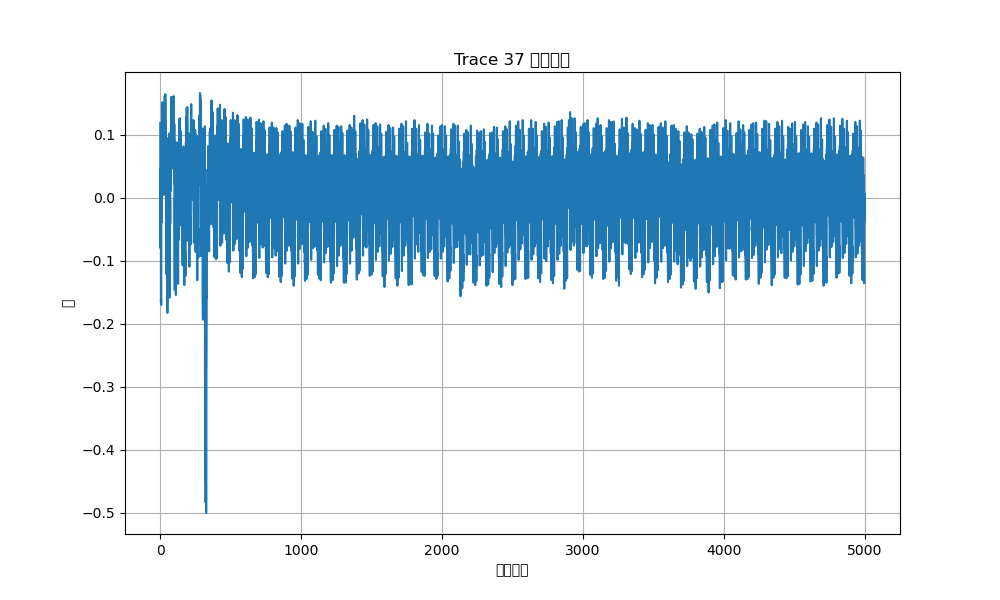
每40组曲线中,会有一组曲线的最大波动处横坐标明显右移,例如上图第37组曲线最大波动处相比于第36组以及其他1-40组的最大波动处都有一定程度右移。推测是密码错误时会出现最大波动,而第37组最大波动右移代表着当前输入的密码字符是正确的,错误发生在下一位。
使用这种方法可以找到每40组曲线中最特殊的一组,并映射为相应的字符。(除了第481组到第520组,因此认为密码只有12位)
特殊曲线到字符的映射脚本如下:
1 | data = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', |
得到结果_ciscn_2024_,因此 flag 为:
1 | flag{_ciscn_2024_} |
题目给了一个字符串AnU7NnR4NassOGp3BDJgAGonMaJayTwrBqZ3ODMoMWxgMnFdNqtdMTM9,没有说明经过何种处理。
放到 CyberChef 选择 Encrption / Encoding 逐个尝试,用 Atbash Cipher 解密后 Base64 解码,得到:
1 | fa{2b838a-97ad-e9f743lgbb07-ce47-6e02804c} |
根据题目的提示想到栅栏密码,将字符串对半分,然后Z形拼接就能得到 flag:
1 | flag{b2bb0873-8cae-4977-a6de-0e298f0744c3} |
IDA反编译,注意到程序中设置随机数种子的代码:
1 | v3 = time(0LL); |
实际上随机数种子恒为0x60000000,因此该程序中的随机数都可以确定,可以使用 ctypes 来调用 libc 库设置相应的随机数种子,获取每一次调用 rand() 返回的随机数。剩下的就是根据反编译的程序使用 z3 进行约束求解,exp 如下:
1 | from pwn import * |
其中第三次获取38个随机数时,我使用 ctypes 得到的随机数与实际的随机数不符,因此直接在 gdb 中打印 v31 这个数组在与随机数异或前后的值,得到第三轮的38个随机数。不清楚是什么导致了这种差异,但或许这就是题目提示“动静结合”的原因?
最后得到flag:
1 | flag{78bace5989660ee38f1fd980a4b4fbcd} |
一道简单的栈溢出+ROP题目,一开始被 golang 唬住了,逆向了一会儿没找到缓冲区的大小,然后直接在 gdb 中看就清楚多了。
首先checksec:
1 | Arch: amd64-64-little |
有栈溢出 + 没有canary + 没有PIE + gadgets = 简单 ROP
找到要用的gadgets,构造 ROP chain ;在 gdb 中计算出缓冲区开头与返回地址的距离为0x1d0字节,加上填充就得到 payload。exp 如下:
1 | from pwn import * |
有 syscall 但是没有 syscall ; ret ,因此我们的 ROP chain 最多只能有一次 raw syscall ,因此 read 选择使用函数地址而不是 raw syscall。get shell 之后得到 flag :
1 | flag{08c559f9-81f7-4c74-a983-9eb59502de34} |
首先用 IDA 反编译程序,在程序中发现以下漏洞:
再根据题目名称的提示可以知道,可以使用 House of Orange 进行攻击(利用 heap overflow 和 read after free),泄露出 libc 地址和堆地址。由于 libc 的版本为2.23,因此最简便的方法就是劫持 __malloc_hook 。使用 pwndbg 的 find_fake_fast 命令找到用于覆盖 __malloc_hook 内容的 fast bin 地址,然后利用 write after free 劫持 fast bin ,使其返回该 chunk ,然后将__realloc_hook写为one_gadget,将__malloc_hook写为realloc,这样做更容易满足one_gadget条件。
利用代码如下:
1 | from pwn import * |
get shell 并得到 flag :
1 | flag{2a6de11d-8a93-484d-9444-7d1046c55134} |
我刚开始放 payload 的堆选了0x80大小,根本放不下 ROP chain ,直接导致比赛结束时没来得及将这题做完,赛后十来分钟改了个大小就打通了。
又一道堆题,但是使用 seccomp 限制了系统调用:
1 | $ seccomp-tools dump ./EzHeap |
因此很容易想到先用 mprotect 更改页面权限,然后 orw 直接读 flag。但是我最后没有使用 mprotect ,直接在栈上构造 ROP chain 来进行 orw 。
分析程序,发现漏洞:
而且最多允许我们 malloc 80个堆块,因此应该有不少利用方法。我主要利用 tcache poisoning 。攻击思路如下:
首先利用堆溢出和相邻内存泄露,通过程序内已经有的 unsorted bins 等堆块,泄露 libc 和 heap 地址
计算 libc 中 __environ 的地址,利用 tcache poisoning 获得该地址处的堆块进行读,泄露 stack 地址
libc 版本为2.35,因此要手动 safe link
在某个堆块中写入 flag\x00 用于 orw ,搜集 gadgets 构造 ROP chain 。值得注意的是不能直接调用库函数 orw ,因为库函数的open 往往使用 openat 系统调用,会被禁止。因此我直接选择全部使用 syscall ; ret gadget ,这也是导致我 payload 巨大的原因。
在 malloc_heap 操作对应函数的 ret 处下断点,计算此时 stack 地址与泄露 stack 地址的偏移,然后再利用 tcache poisoning 获得目标地址附近(target_stack-0x8,因为要16字节对齐且不能破坏canary)的堆块进行写。payload 为 8 字节的 rbp 填充加上 ROP chain 。malloc_heap 返回时会被劫持到该 ROP chain 。
exp 如下:
1 | from pwn import * |
最后得到 flag :
1 | flag{c9112d19-27e3-41ec-9957-fefb3f109229} |
在 discord 上认识了一群来自世界各地的 ctfer,不过大家都不是什么老赛棍,just ctf for fun!
有人在频道里提议参加TBTL CTF 2024,然后就组了个队。比赛时间2天,实际上没什么时间打,做了几个方向的新手友好题。不过队里有个哥们 web 方向 3/4,最后队伍排名36。

这是一道简单的社工题。
mp3 文件里有这道题的提示:
该标志的格式如常,我们的合作伙伴云海连锁控股有限公司总部位于海南岛海口附近。找到距离他们的办事处最近的银行。标志内的内容是该银行的统一社会信用代码。代码已以91开始,以56结束。
首先搜这家公司,可以通过这个网站找到其地址,打开高德地图搜索“云海链8831栋”可以找到该公司位置,然后再搜周边——银行,可以看到最近的银行是海南澄迈农村商业银行股份有限公司科技支行。
然后我们搜索其社会信用代码,得到91469027MA5TRBAW56。
因此 flag 为 TBTL{91469027MA5TRBAW56}。
这是一道非常简单的数字签名攻击题目。我们的目标是获取bytes_to_long(b'I challenge you to sign this message!')的数字签名。同时,我们可以提供任何消息给签名者进行数字签名,因此很容易想到这是 RSA 数字签名中的选择消息攻击。
我们假设m = bytes_to_long(b'I challenge you to sign this message!') ,我们的目标是获取其数字签名:
$$ s = m^{d};mod;n$$
首先,我们让签名者为任意选择的消息 m1 进行签名(这里我选用m1 = bytes_to_long(b'BeaCox')),获取对应的签名:
$$s_1=m_{1}^{d};mod;n$$
然后,我们计算
$$m_2:=m⋅m_{1}^{−1};mod;n$$
并让签名者为其签名,得到
$$s_2=m_2^d;mod;n$$
由于
$$s≡s1⋅s2≡m_1^d⋅m_2^d≡m_1^d⋅(m⋅m_1^{-1})^d≡m_1^d⋅m^d⋅m_1^{-d}≡m^d;(mod;n)$$
我们很容易得到
$$s=s1⋅s2;mod;n$$
利用代码如下:
1 | # https://crypto.stackexchange.com/questions/35644/chosen-message-attack-rsa-signature |
这是一道简单的逆向题。从 ida 获取静态的数组,然后根据反编译的代码写 z3 的约束,编写 python 脚本来得到正确的输入。
1 | # input is 31*31 bit(0 or 1) string |
我们会得到一个 31*31 的由0和1组成的矩阵:
1 | 0000000000000000000000000000000 |
可以看到这个矩阵的周围一圈都是0,如果把周围这一圈0都去掉,那么就是一个29*29的矩阵。把0看成白色,1看成黑色,那么这个矩阵看起来就是一个29*29的第三代二维码,写脚本将01矩阵转换为二维码图片:
1 | # convert to qrcode |
扫描二维码就可以获得 flag 。
这是一道利用了scanf函数特性的pwn题。
这道题允许我们输入20个4字节长的整数,然后输出这20个整数的平均值。但是存储这些整数的内存区域含有先前读取的flag。
这个程序使用20个 __isoc99_scanf("%d", &v3[i]); 来读取我们的输入。如果我们输入了一个字符,那么从此以后的scanf都会直接返回-1,导致对应内存区域的4字节为原来的值,最终导致内存泄漏。
我的想法是:首先输入19个0,然后输入一个a,就可以得到目标内存区域的第20个4字节(data[19]);然后启动另一个程序,输入18个0,然后输入一个a,就可以得到data[18]+data[19],计算可得data[18],依次类推可以得到目标区域的所有20*4个字节。然后就可以重构出flag。
1 | from pwn import * |
Fun!!! 感谢主办方,难度梯度做得很好。
记录一下打CTF以来做出题目最多的一次。这次的题目是 SJTU CTF 2024 校内赛和第一届 GEEKCTF 共用的。所有题目都可以在GEEKCTF官网找到,由于我是在校内平台做的,flag可能会略有不同,但是解题的方法应该是一样的。
本题的漏洞点是任意文件读取+特殊字符绕过upper/lower。
攻击流程如下:
选一个主题后,在登录页面抓包,发现有一个redirectCustomAsset路由
1 | Accept-Encoding: gzip, deflate |
看上去是用来读取不同主题的css文件,但是是相对于网站根目录的相对路径。因此猜测可以读取网站目录下的所有文件。
在登陆页面查看网页源代码,发现body后面有一串看不懂的编码,放到cyberchef里一个个试发现是Base85:
其中比较重要的是app.py和populate.py。
将Cookie改成asset=app.py会回显hacker,改成asset=assets/css/../../app.py即可得到网站的源代码。
在app.py里面硬编码了用户名和密码:
1 | def isEqual(a, b): |
但是isEqual要求用户名和密码都需要满足小写化后不等于硬编码的用户名/密码,大写化后又要等于。第一眼看懵了,小写不相等但是大写相等?问下claude:
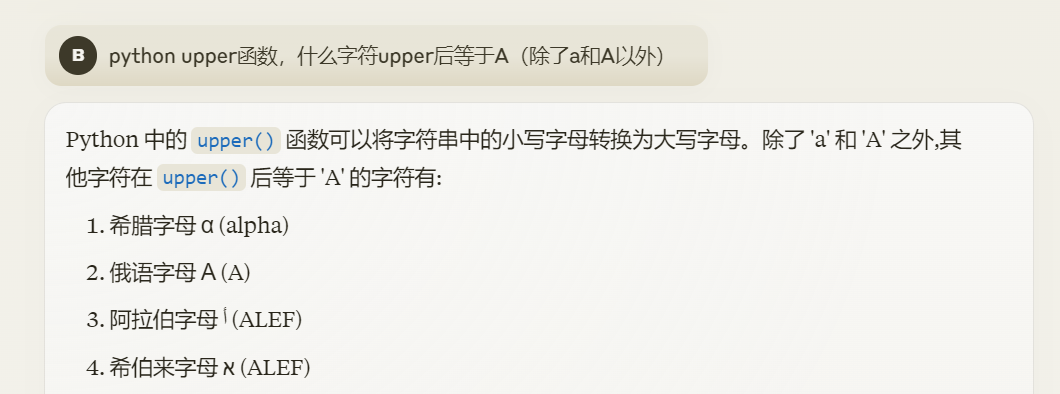
进一步搜索发现upper对unicode特殊字符的处理有些问题,用unicode包裹起来才会得到正确的大写。不过claude给的字符似乎不对,直接用Python遍历unicode字符好了:
1 | def find_replacement_char(ch): |
只找到了i的替代字符ı,s的替代字符ſ。输入用户名alıce,密码ſtart2024,登录成功!
再看看populate.py:
1 | import os |
也就是说“type=secrets”会给我们flag,但是在app.py里还有过滤:
1 | type = request.args.get("type", "notes").strip() |
我们需要让and前面的逻辑表达式为否才能够不返回错误、获得flag。
因此要想查看flag,type的参数需要是secrets的变体,页面上给secrets的ts划了下划线,猜测是提示将这两个字符换成特殊字符。
打开Burp的intruder,payload选用simple list,从网上下载了一个特殊字符的列表来爆破ts。
最后ts替换成ƾ时,response的length不一样,点进去看详情就能看到flag。
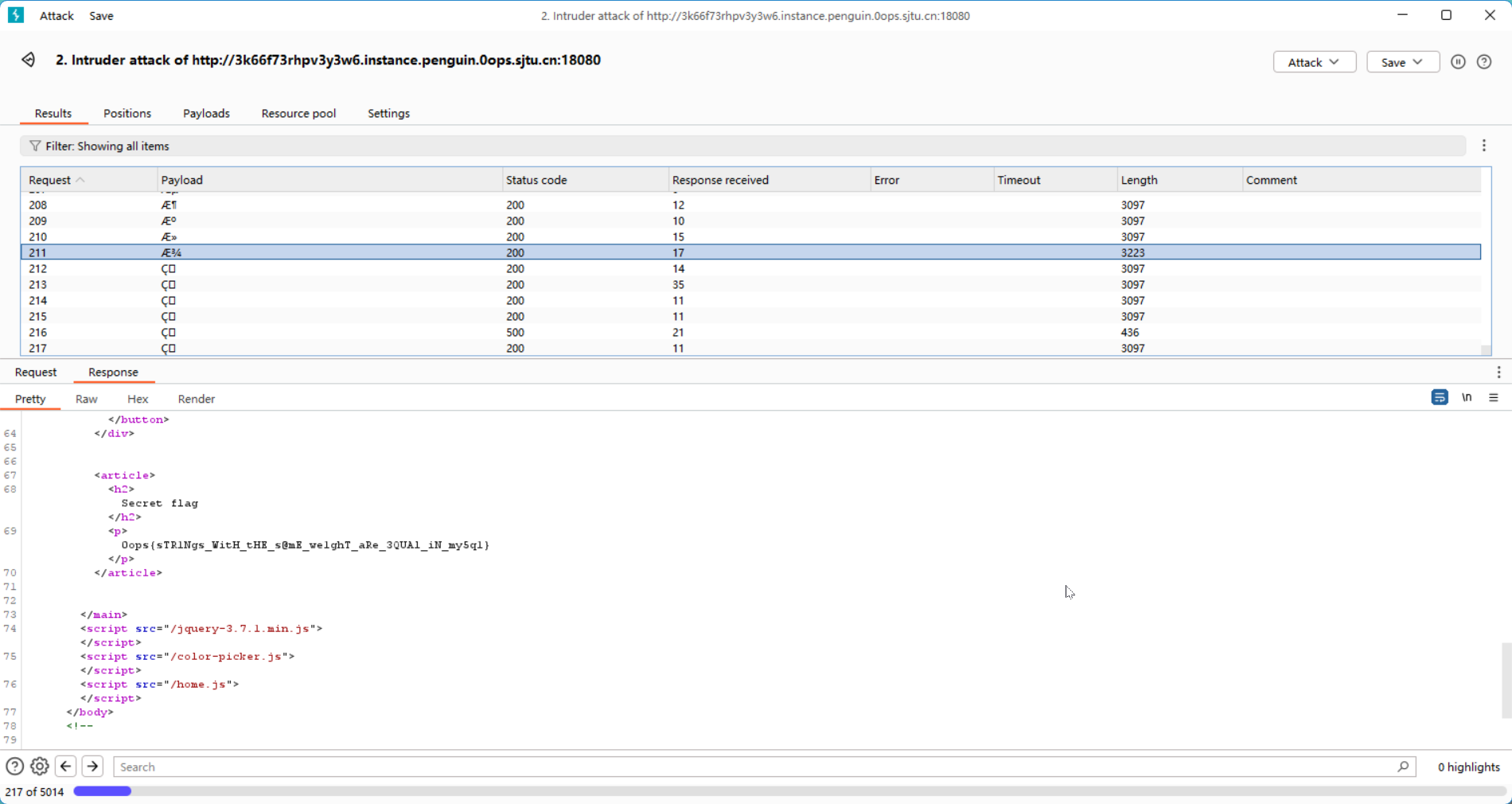
flag:
1 | 0ops{sTR1Ngs_WitH_tHE_s@mE_we1ghT_aRe_3QUAl_iN_my5q1} |
本题的漏洞点是整数溢出和栈溢出。但是用不到,只需要逆向出密码。
攻击流程如下:
首先要输入密码登录,密码通过一个加密算法后与J8ITC7oaC7ofwTEbACM9zD4mC7oayqY9C7o9Kd==对比,长得很像base64,但是用base64解码出来不对。把sub_12E9的加密函数丢给claude,直接逆出了密码。。。
1 | def decode(encoded_data): |
但是好像有点问题,将À改成?就对了。
一开始没有在本地新建flag文件,ida里面还把win函数看漏了。。。导致还在继续用栈溢出去劫持control flow调用win,其实逆向出密码就可以得到flag。
完整exp:
1 | nc 111.186.57.85 40310 |
flag:
1 | 0ops{U_r_th3_ma5ter_0f_ba5e64} |
本题的漏洞点是整数溢出和栈溢出。
攻击流程如下:
首先checksec:
1 | Arch: amd64-64-little |
保护全开。然后看main函数,发现供用户输入的字符串在栈上,大小是264字节,乍一看用户也只能输入0x100即256字节,很安全。但是在实现edit功能的函数里面:
1 | lea rax, aLld ; "%lld" |
可以发现,允许用户输入的是有符号数,而比较的时候却是根据无符号数进行比较,然后在读取用户输入的时候又使用其低32位作为允许输入的长度,因此会出现类似0xffffffff00000109 < 0x8的情况,却允许用户输入0x109个字节。
为了能够输入我们想要的长度,需要将0xffffffff00000109这样的数转换成相应的负数:
1 | def convert_to_signed(num): |
至此,我们总结一下能够利用的漏洞:
可以利用整数溢出在栈上写非常长的内容,因此可以利用栈溢出劫持程序控制流。
但是由于保护全开且没有win函数,因此我们需要先leak canary,然后leak libc,最后在栈上布局 ROP chain 来 get shell。
我们先在sub_170e函数(读取用户输入的函数)处下一个断点,观察栈的布局。
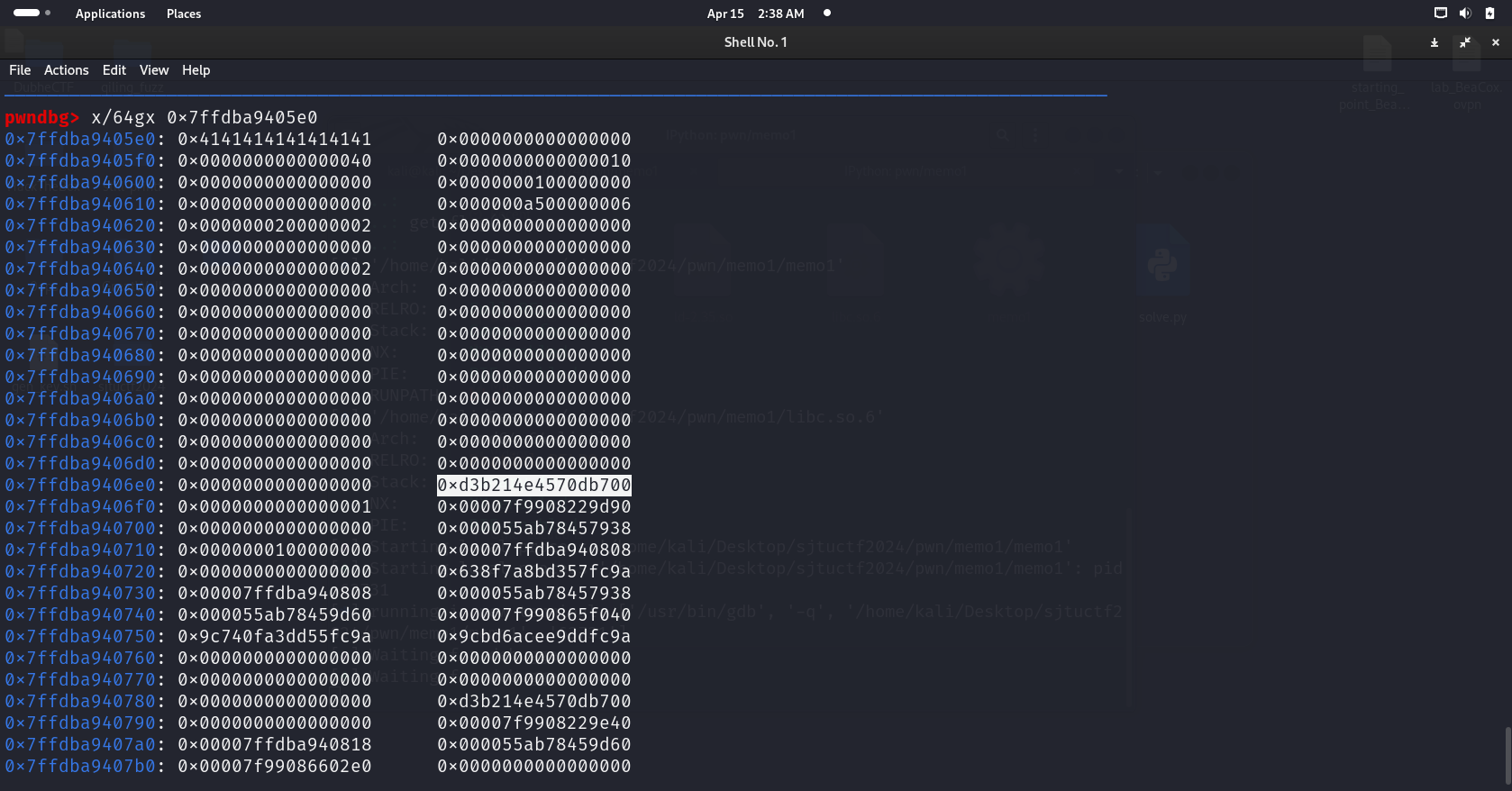
发现canary距离用户输入的起始位置为0x108字节,因此我们需要覆盖用户输入的前0x109字节为非0字符,然后调用show就可以连带canary一起输出出来。而读取用户输入的sub_170e函数是一个带0截断的函数:当我们输入\n会被替换成\x00,如果长度参数正好等于我们输入的长度,就不会添0。因此我们需要让其长度参数恰好等于0x109,也就是在调用edit时,输入的长度为convert_to_signed(0x109)。然后输入0x109个A,再调用show,最后7位就是canary的高7位。
用户输入的起始位置加上0x118个字节是libc的地址,与基地址的偏移是0x29d90,使用和leak canary几乎一样的方法可以leak libc。
最后就是在栈上布局 rop chain 了。因为有libc,因此可以直接用libc的gadgets,使用pwntools构造一个execve(‘/bin/sh’,0,0)的Rop,在栈上canary的位置填入canary,返回地址处布局rop chain,即可得到shell。
1 | rop = ROP(libc) |
完整exp:
1 | from pwn import * |
flag:
1 | 0ops{5t4ck_0v3rfl0w_1s_d4ng3r0u5_233} |
本题的考察点正如题名是shellcode,但是seccomp只允许了open和read,没有write,因此需要利用循环来实现类似侧信道攻击。另外,对shellcode的字节做了限制:
偶数索引处的字节必须是偶数,奇数索引处的字节必须是奇数
1 | for ( i = 0; i < v5; ++i ) |
大于0x80的奇数不能用
1 | mov rax, [rbp+buf] |
这段实际上是将shellcode的字节作为一字节的有符号数来对2取模,因此类似于0x81这样的大于0x80的奇数模2后的结果是-1而不是1,但是对索引的取模是看作无符号数,因此奇数索引处取模是1而不等于-1。这也就代表着大于0x80的奇数不能出现在shellcode中,这点非常坑。。。比前一点限制花了我更多时间。因为这个限制相当于把一般的jmp长跳转、call、ret、syscall全都禁止掉了。
思路:
由于我们还要进行侧信道攻击,不可能每爆破一个字节都构造一个能满足要求的shellcode,因此考虑分两个阶段:
每个二阶段shellcode爆破一个字节:将[flag_addr+i]与每个可见字符作比较,相等时进入死循环,通过对时间的测量就能知道flag的每个字节是哪个字符值。
开凑:
先凑一阶段的shellcode。由于限制非常多,因此考虑尽量利用栈上已有的内容和寄存器中已有的内容(pop和push某个寄存器都是一字节的指令,不同寄存器奇偶性质不同,很容易满足限制的要求)。

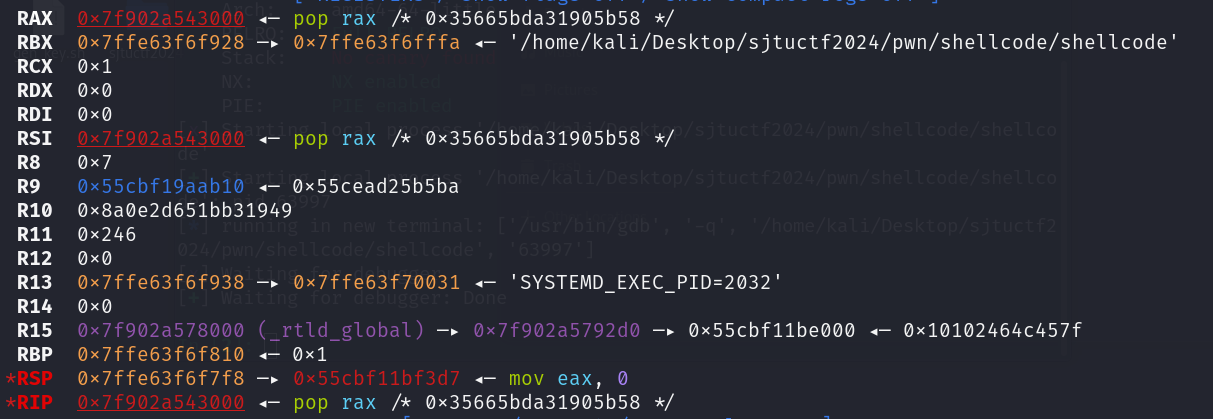
rsp的最顶端是返回地址即main+0xc4,我们将这个地址pop到rax,然后对rax进行xor操作,可以得到read@plt,方便后续调用read库函数。有了这个思路,我们就需要布置好read的参数。rdi现在恰好是0,符合我们的要求,不去修改。rsi也是输入的起始地址不需要修改。rdx需要修改为我们想要输入的长度,经过观察rsp+0x8处的低8位正好是我们一阶段输入的长度,因此我们只需要将rsp+0x8的低8位值放到rdx中去即可:
1 | pop rax |
这样就已经将read@plt放到了rax里面,并布置好了rdi, rsi 和 rdx。接下来的问题就是如何调用rax中存储的函数。已知jmp的长跳转、call、ret、syscall都不符合这道题的过滤要求。怎么办?想起之前用ROPgadget的时候看到ret{num}这种形式的指令,去搜了一下,发现是ret之后,令rsp增加num字节。字节码是:b'\xc2\x01\x00'正好满足要求。但是又出现一个新的问题:
栈指针增长奇数个字节后,我们就无法控制返回地址了。
因此想到,如果在ret {num}之前先让栈增长或者减少奇数字节,而且这个命令能够通过过滤,就能解决这个问题。搜索发现有一个enter指令:
enter指令的完整格式是:
1 | enter bytes, level |
其中:
bytes是一个立即数,表示当前函数需要在栈上分配的空间大小(以字节为单位)。这个值通常就是函数内局部变量所需的大小。level是另一个立即数,表示嵌套函数调用的层数。通常这个值为 0。我这里用一个enter 0x1, 0x3,level是我随便指定的,在gdb里面看效果:
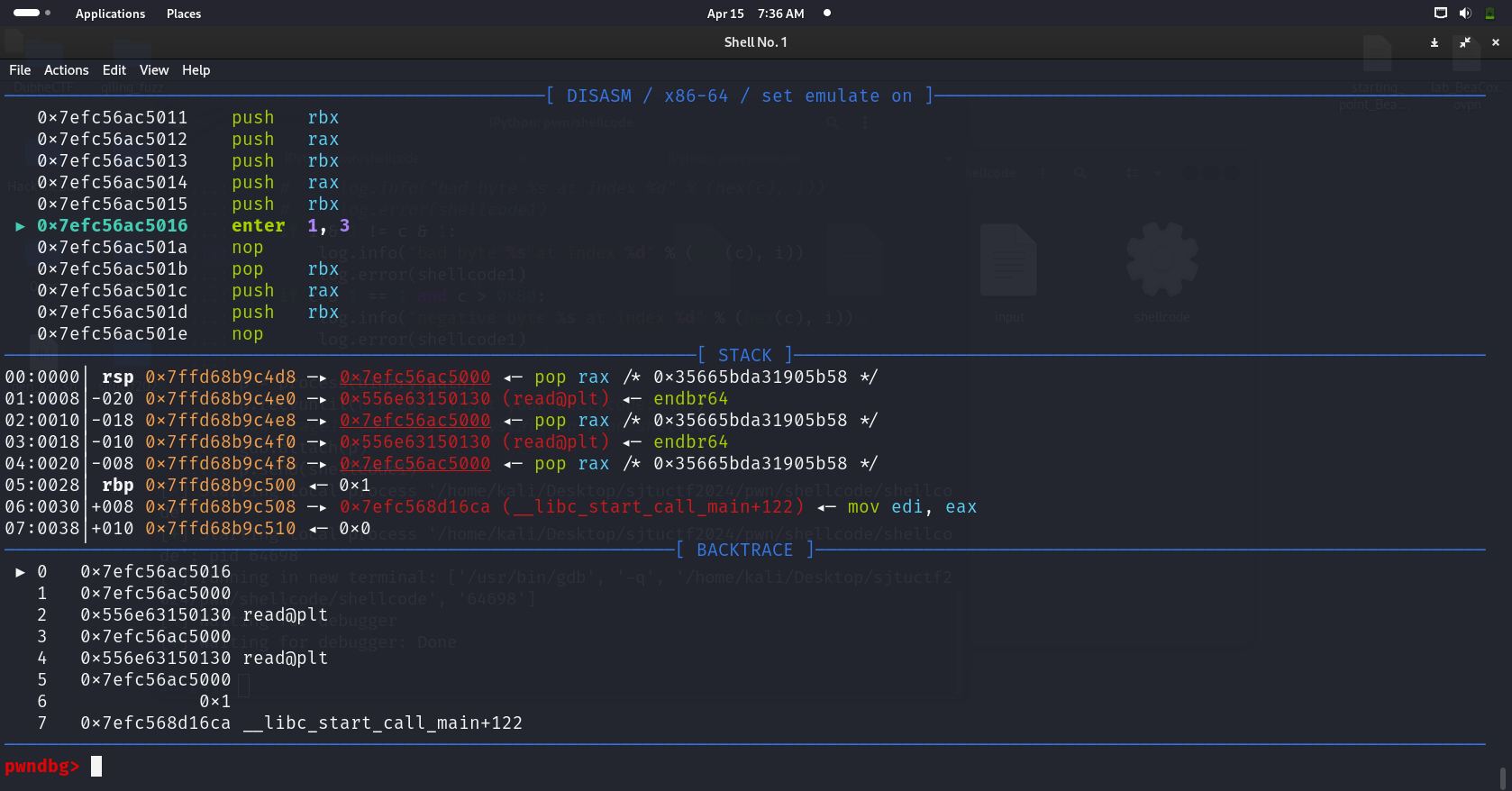
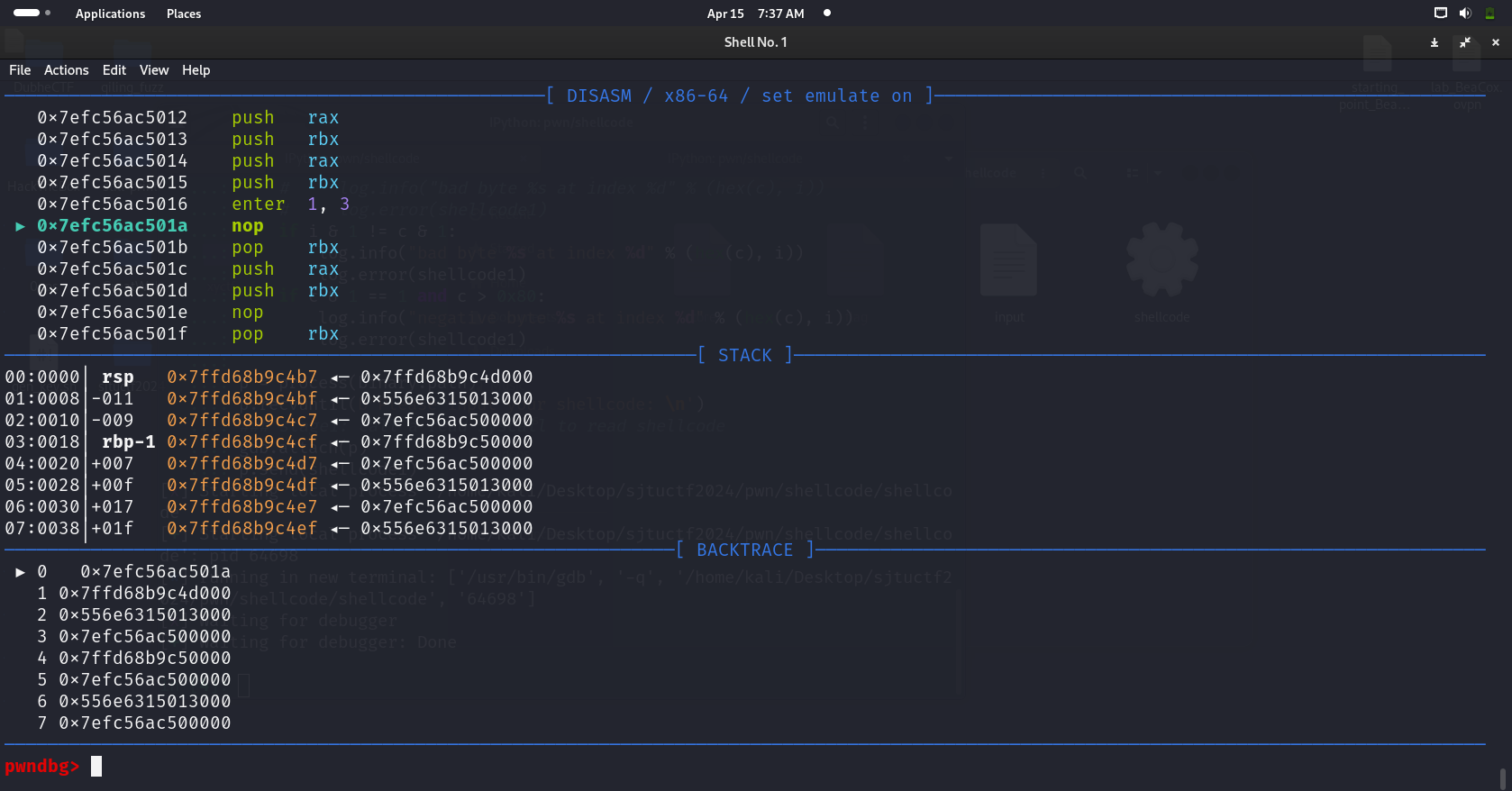
栈指针减少了0x21字节,那么我们再用ret 9就可以让栈重新和8字节对齐,在那之前先把read@plt的地址push入栈,ret的时候才能返回到read,等后面栈指针增加和8字节对齐的时候可以返回到我们在enter之前push入栈的shellcode地址。
1 | nop |
至此第一阶段就构造完成了,第二阶段的shellcode就是open(‘flag’, 0)然后read第i个索引处的字节,与各个可见字符进行比较,如果相等就死循环,通过时间判断是否命中,逐字节爆破到}为止,完整exp如下:
1 | # no write for us |
flag:
1 | 0ops{practice_handwrite_shellcode} |
本题的考察点是deflat去混淆和tcache劫持。
其实题目对deflat的提示很明显,但是我一开始没往这方面向,直到出flag才知道要用deflat,一开始是自己手动去混淆的:
先看明白了每种操作对应一个opcode,然后找==,然后根据i=xxxxx去找casexxxxx,有if的就猜测可能是对什么进行判断(比如索引、size),然后选一个i去找case……最后硬是把程序的主要逻辑逆向出来了:
48879: 退出程序
4112:堆块写,但是最后一位由程序置零(edit_0_end)
e.g. edit_0_end(index, payload)
会对index所对应位置的size和address做非空检查,且0<=index<31,payload的长度实际上最多比size少1,最后一字节会被置0
768: malloc
e.g. malloc(index, size, payload)
会对index所对应位置的size和address做非空检查,且0<=index<31,payload的长度实际上最多比size少1,最后一字节会被置0
2989: 堆块写(edit)
e.g. edit(index, payload)
会对index所对应位置的size和address做非空检查,且0<=index<31,payload的长度恰好等于size
4919: free
e.g.free(index)
会检查0<=inex<31,检查address处是否已经为空,然后将对应address和size都置零。
57005: 堆块读(puts)
会对index所对应位置的size和address做非空检查,且0<=index<31,然后puts堆块内容
但是这里的0截断并没有off-by-null漏洞,在how2heap找了半天找不到利用方法。于是在gdb里先试着:
1 | from pwn import * |
发现mallo个两次0x100大小的堆块程序就退出了,于是在第一次后面把gdb附上去:
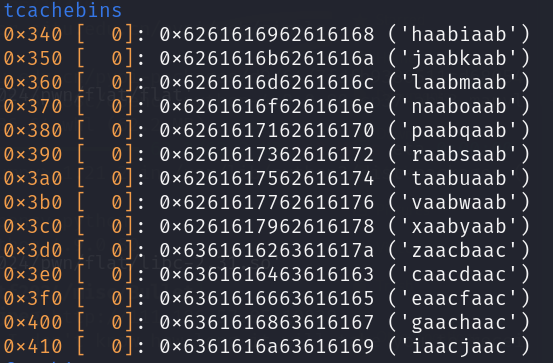
十分离谱……我到现在也没弄明白这个漏洞是哪里来的。
换成0x80及以下似乎就没这种情况,0x90的时候链表有两个值,分别是我们输入的0x80处和0x88处,也就是说我们在0x80和0x88处写上合法的地址,下一次malloc相应大小的chunk就能控制我们输入的地址。
checksec一下:
1 | Arch: amd64-64-little |
那么我们现在需要做的就很清晰:
首先,准备好用于leak和劫持的堆块,以及写有/bin/sh的堆块;然后malloc一个可用大小为0x90的堆块,malloc一个可用大小为0x330(实际大小为0x340)的堆块并free掉,使得tcache的0x340大小链表有一项。然后往0x90大小的堆块里面填满heap_manager地址(也就是该程序用来管理堆块的区域起始地址)。这样当我们再malloc一个可用大小为0x330到0x338大小的堆块时,就会返回heap_manager的地址。我们往这里面填入0x1000和free_got的地址,这样程序自定义的堆管理器就会认为index0处之前malloc了一个可用大小为0x1000的堆块,且位于free_got。因此我们这时再puts(0)就不会报错,也就能够leak出libc中free的地址,也就知道了libc的基地址。然后利用这个基地址知道system的地址,往0写入这个地址,也就将free劫持到system。最后我们free(1),1是我们之前放/bin/sh的地方,此时执行system('/bin/sh'),得到shell。
完整exp:
1 | from pwn import * |
flag:
1 | 0ops{learning_deflat_trick_to_defeat_ollvm} |
这道题的考察点是ptrace和strace的用法。
peer程序会调用puppet程序,并使用ptrace来在不同运行时刻监视peer程序并修改其内存/寄存器的值。
先从网上学习了下ptrace的用法,主要关注PTRACE_POKEDATA, PTRACE_SETREGS因为这两个会修改被监视子程序的内存/寄存器。
puppet程序的逻辑是读取一个输入,长度需要为48字节,然后逐字节与0x28异或,最后与ct区域的48字节做比较。
建议使用strace观察程序运行过程中ptrace相关内容:
1 | strace ./peer |
peer程序的主要逻辑可以通过观察PTRACE_POKEDATA, PTRACE_SETREGS和相应的ida伪代码得到:
对输入的48字节做下面的逻辑:
在异或0x28后,劫持程序,对每个字节做如下修改:
1 | v25[0] = 0xA39C3E6994313F40LL; |
每个字节分别与peer中此时的v25中对应字节相加,舍去进位。
最后再与puppet程序中ct区域的48字节作比较,需要相等。整个过程都是相对简单的可逆过程,将算法反过来即可。完整exp如下:
1 | from pwn import * |
flag:
1 | 0ops{tr@cE_traC1Ng_tRAc3d_TRaces_z2CcT8SjWre0oP} |
本题考查的是二维码的结构和标准qrazybox的使用。
之前在做hackergame还是geekgame的时候碰到一道华维码,是华容道和二维码还原的结合。题目没做出来,但是在群里看到个二维码仙人,整天在群里发他还原二维码的过程。这下真用上了,快说谢谢二维码仙人。
贴一个二维码仙人的二维码教程
要用到的工具是qrazybox
由于定位块缺失,我先直接根据图片把已知的黑色白色都填充上,然后一个一个试纠错等级,发现只有M0是符合的,然后用qrazybox的tools把padding bits补上:
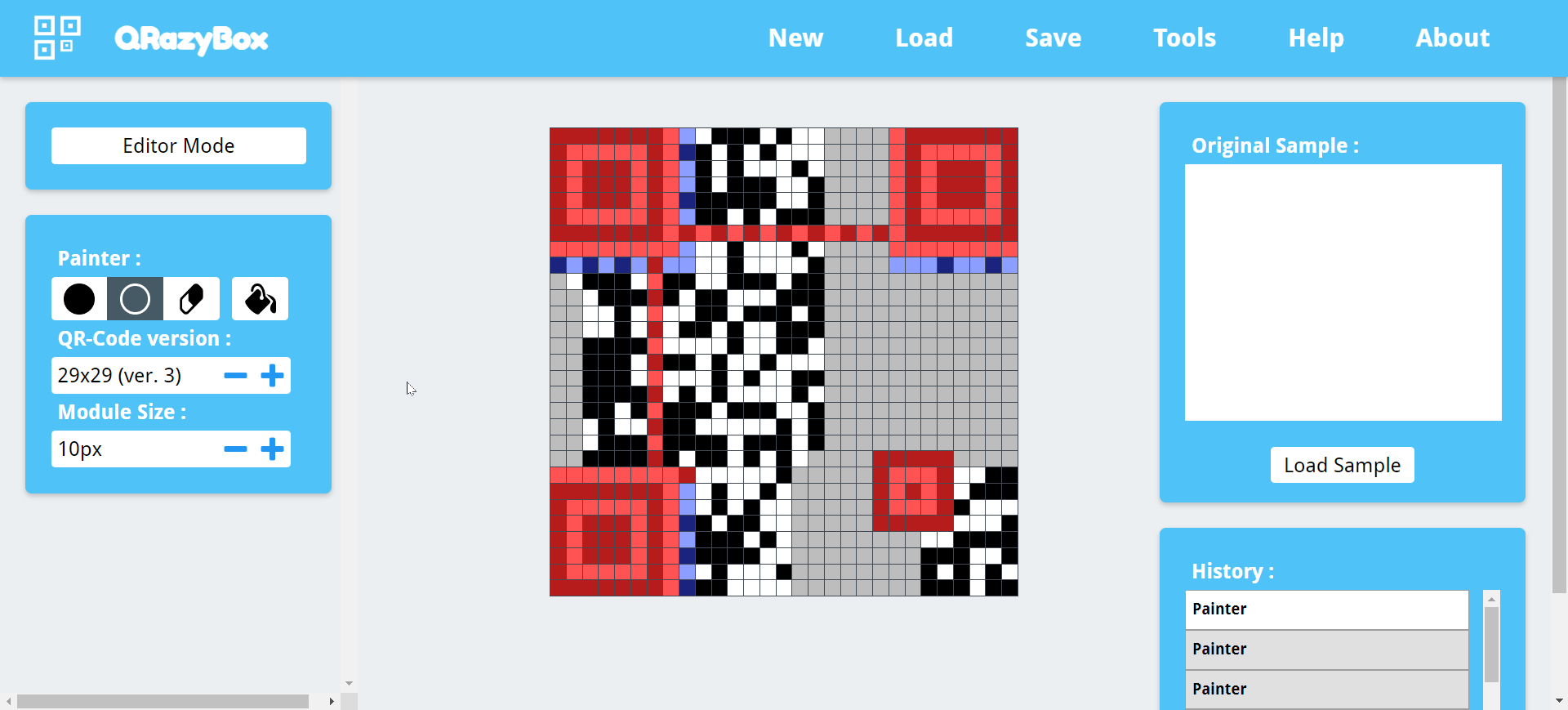
但是缺失的内容实在太多了,无论是直接提取还是用Reed-Solomon Decoder都得不到flag,但是通过Data Sequence Analysis可以看到message data有一个},而题目已经告诉我们这题的flag格式为flag{.*},根据二维码格式,我们将前5位message data修改位flag{,这时候再用Reed-Solomon Decoder已经可以得到flag了。
修改数据后的结果:
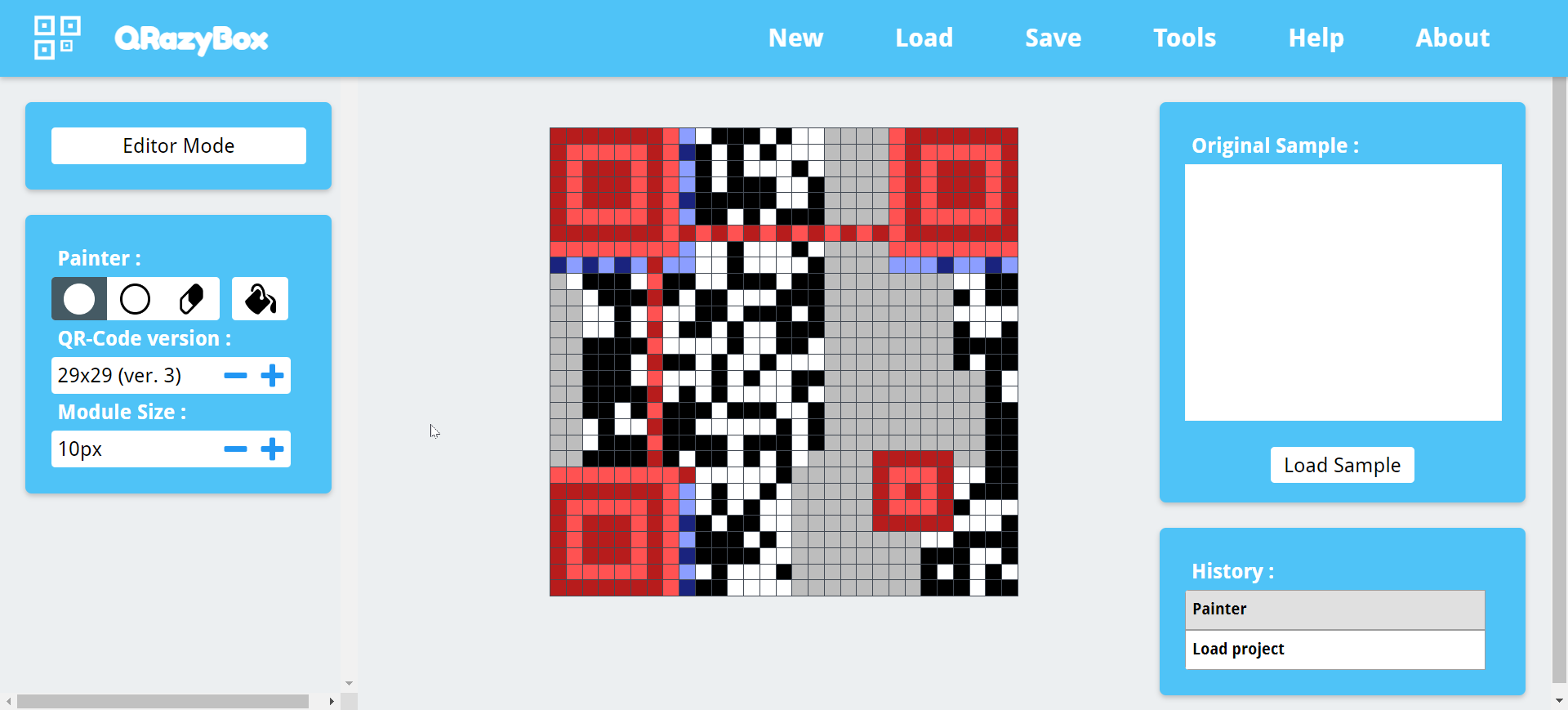
flag:
1 | flag{D4+4_2e(0\/3R_v_!5_S0_3a5_v} |
本题考察的是视力和对数据的处理能力。
在github的commit记录最后可以看到:
1 | import gzip; import base64; gzip.decompress(base64.b64decode('H4sIAAAAAAACA5Pv5mAAASbmt3cNuf9EzT3+sN5nQrdr2jIOrcbXJmHROjnJAouEuzN5jcq4Fbf6bN1wVlfNYInA9KvHri/k2HjhUVbxzHOHlB5vNdhWdDOpzPyo0Yy7S+6LFzyoXBVc/0r/+ffe+TVfEr8u/dF93/3if9td8//+Ff//8WK4HQMUNL7+V9J/3fBA+2Ojea/lmaCiC7PLMzf1Mt3zjTvJCBU6+Pp00v6/Ah92xQpbQoUUKm7azN2meyBZkk/cFi52vlpmbXQD0LhshLq3er7XdB2+533y4oOKccTFi/1+63HgdZnvE6hQw4PUzyW3tjH0p1rEfIGL2b4v3JLH2He6Yt1TuNjW3SaR2xnu7j6pjbCiNvLNdmXG9bdNJzJDxZqmn72ceZvJZtrDgotwse97jl/cxWqh93jnNLjY9XeXUu4ylbxXW49wytfUjff7WPbkXXdBuNjMf3ku94eItsOu/DCxe5/l3F+LPdjR8zwKoW639+RS7gt7Z++ZhLBi+tE6a6HRwBsNvNHAGw280cAbDbzRwBsNPETgff/8c/3l6bfX1355+POl/P+f7P/n1n17/L7239/8ufs8Ztf/fWr+mP/P/rrvL+vrbP59m1/39Wf/vh/T///y/vb102R/u9/b4///3m4v9+/D9vof7+bv/zX7v2bdr375Xe//6DOe7GOObudnAAAdRZxfbAoAAA==')) |
运行这段代码发现处理后的数据还是1f8b开头,推断仍然是gzip。直接写到文件里去:
1 | import gzip |
然后再终端反复解压缩,得到二进制文件后strings一下:
1 | gzip -d out.gz |
就可以得到flag:
1 | flag{760671da3ca23cae060262190c01e575873c72e6} |
本题考查的是写脚本的能力,大概。
pow challenge 应该是区块链中的概念?但是和这道题关系不大,这题的pow challenge直接让AI就能写,要花太长时间的challenge就跳过好了。
给的server.py并不会输出第几张图片判断错了,但是实际交互时显示了。而且在我把所有图片都无重复地保存下来后发现总共只有100张图片,服务器会每次选20张让我们判断真伪,因此我们可以先将所有图片都随便打上标签,然后根据标签去向服务器发送答案,服务器每次都会给我们纠错一张,我们根据错误信息修改对应图片的标签,很快就能将所有图片的标签都修改正确。这时无论服务器选哪20张我们都能给出正确的答案。
保存图片的脚本:
1 | import hashlib |
这道题的标签我一开始是用模型打的,但是准确率并不高。exp如下:
1 | import hashlib |
flag:
1 | flag{DeepFake_1s_Ea5y_aNd_1ntere5t1ng!} |
本题考察的是谷歌识图的能力。
下载图片和之前一样,这道题我下载下来只有86张图片。我全部拿去谷歌识图,能搜到的大多数是unsplash上的图片。能搜到的我都标记Y,搜不到的都标记N。准确率似乎极高。。。跑个几次就出flag了。因此主要工作量在于我手动谷歌识图,但是应该可以写代码调用API?
exp如下:
1 | import hashlib |
flag:
1 | flag{Revenge_1s_Ea5y_aNd_1ntere5t1ng!} |
本题考察的是信息检索能力和动手能力。
几乎全靠这篇文章:
https://wumb0.in/extracting-and-diffing-ms-patches-in-2020.html
根据文章提到的步骤把msu里面的cab提取出来:
1 | mkdir content |
发现f和r文件夹下都有curl.exe。那么我们要做的就是从delta和curl.exe恢复出一个二进制文件。
需要利用作者编写的delta_patch.py。但是直接将题目给的f和r喂进去是行不通的。
文中有这么一段:
To generate the binaries I want I’m going to apply the reverse delta and then each forward delta, creating two output files:
2
3
4
5
6
Applied 2 patches successfully
Final hash: zZC/JZ+y5ZLrqTvhRVNf1/79C4ZYwXgmZ+DZBMoq8ek=
PS > python X:\Patches\tools\delta_patch.py -i ntoskrnl.exe -o ntoskrnl.2020-08.exe .\r\ntoskrnl.exe X:\Patches\x64\1903\2020\2020-08\x64\os-kernel_10.0.18362.1016\f\ntoskrnl.exe
Applied 2 patches successfully
Final hash: UZw7bE231NL2R0S4yBNT1nmDW8PQ83u9rjp91AiCrUQ=
何意呢,目测是说:
我们有一个比较新的文件,一个旧补丁,一个处于中间的补丁。利用旧补丁的r回到旧版本,再用中间补丁的f就可以生成中间版本。
update.mum里面有一串网址:https://support.macrohard.com/help/5034203
好好好把巨硬改成微软,发现是KB5034203更新,那就把这个msu下载下来,提取出其中curl的f和r。
然后用KB5034203的r回滚到旧版本,用题目给的f生成我们要的二进制文件。
1 | python delta_patch.py -i curl.exe -o curl.patched.exe .\kb5034203\r\curl.exe .\kb114514\amd64_curl_0o0o0o0o0o0o0o0_10.0.19041.9999_none_0o0o0o0o0o0o0o0\f\curl.exe |
得到flag:
1 | flag{ dc1d03c554150a cedca6d71ce394 } |
去掉空格即可。
本题考查图片exif编辑能力和阅读理解能力。
回旋镖是吧。2000年出生的男孩24岁开枪38岁噶了,我作为一个2024年出生的照片也应该38岁时噶,所以应该是2062年。刚开始这个时间戳没搞明白啥意思,一开始文件名里带时间错,后来在图片里加时间戳,后来才猛地想起exif也有时间戳。
用这个网站随便修改了一张图片的exif信息(Modify Date),然后上传:
1 | curl -T 2062.jpeg http://111.186.57.85:10038 |
就能得到flag:
1 | flag{47_7h15_m0m3n7_3duc4710n_h45_c0mp1373d_4_72u1y_c1053d_100p} |
没记flag,学校那个莫名连不上,换geekctf复现的。
ASLR,全称 Address space layout randomization,即地址空间配置随机加载。多数现代的应用程序都会开启 ASLR。目的是防止攻击者事先获知程序的虚拟内存地址,防止攻击者能可靠地跳转到内存的特定位置来利用函数。
在Linux中,ASLR 的实现方式是同一个应用程序每次启动都会被加载到不同的位置。而在 Windows 中,只能保证系统重启后地址的随机性。
究其原因,是对性能和安全性权衡后的结果。由于 Windows 不采用 PIE,因此其 ASLR 的实现需要付出内存代价。 每次将库映射到不同地址时,都会占用更多内存。
当然这也意味着,如果我们在某台 Windows 机器上获取了一次库函数的虚拟地址,在其重启之前,我们都能够继续使用。
在 Linux 中,内核通过task_struct保存并管理进程相关的信息,在 Windows 中起到类似作用的是PEB。当然,还是有许多不同之处。例如 PEB 在用户态中而 task_struct在内核态中。
进程环境块(PEB)是 Windows NT操作系统内部使用的数据结构,用以存储每个进程的运行时数据。
维基百科对 PEB 的描述足够全面,推荐感兴趣的读者继续阅读,值得注意的是中文翻译有些瑕疵。说回到 PEB,PEB 是一个结构体,包含了进程是否被调试、被加载模块的虚拟地址等大量信息。
在 Windows 11 23H2 (2023 Update) 版本的内核中,PEB 的部分定义如下:
1 | //0x7d0 bytes (sizeof) |
在本文中,我们主要关注偏移为 0x18 的 Ldr 字段。为什么?因为它包含了被加载模块(用到的库)的虚拟地址。
在利用之前,或许应该先看看这个字段包含什么内容。我先在 Windbg 中随机打开一个应用程序看看 PEB 及 Ldr 的内容。

在命令框中键入lm,即 list modules,可以看到这个应用加载了5个模块。其中a是程序本身的名字(a.exe),而KERNEL32是我们关心的另一个模块,因为它控制着系统的内存管理、数据的输入输出操作和中断处理,或者换句话说,其中有许多我们可以利用的函数(如WriteFile()用来写)。在不使用调试工具的时候我们无法如此便捷地获取被加载模块的地址,因此我们需要用到 PEB。
在 Windbg 中也可以很方便地查看 PEB 信息:
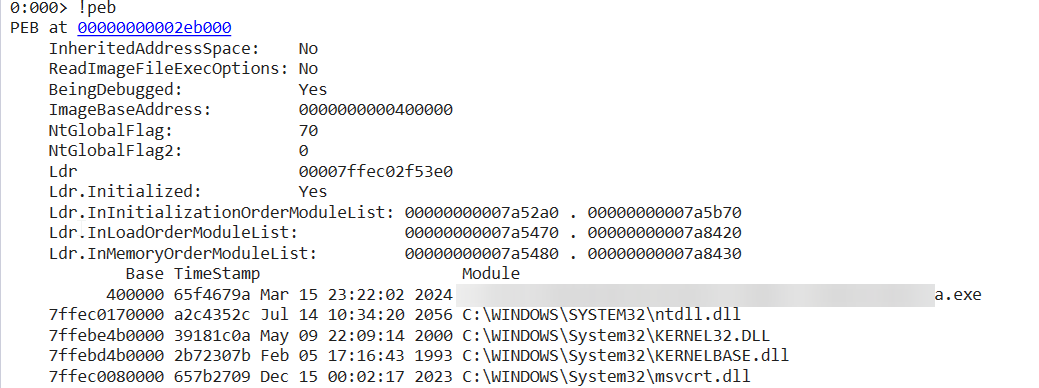
在命令框中键入!peb可以看到 Ldr.InMemoryOrderModuleList下存储着被加载模块地基地址,其中第一个和第三个是我们的目标,其显示的基地址和之前使用lm命令查看到的地址是一致的。
值得一提的是,这些 Modules 正是以 List 链表形式存储的。我们简单地验证一下:

不难发现,在每个条目的开头存储着下一个条目的地址,而偏移 0x20 处存储着被加载模块的基地址。因此当我们表头的地址时,我们可以通过每个链表项跳转到下一个链表项、可以获取每个链表项下模块的基地址。
接下来就是编写 C 代码获取被加载模块虚拟地址的 demo 了。我们先提出尚未解决的几个问题:
先回答第二个问题:Ldr.InMemoryOrderModuleList 相对 Ldr 的偏移是 0x20 。并且在我们编写 C 代码的时候,不需要知道具体的偏移量,只需要知道字段名称即可,相应的库会帮我们处理好偏移量。
接着是第一个问题:Windows 用 FS/GS 寄存器来存储 PEB 的地址,分别对应32位/64位。具体如下:
:后代表偏移量。
解决了这两个问题之后就可以编写 C 代码了:
1 | #include <stdlib.h> |
简单地解释一下流程:
gs 寄存器获取 PEB 地址PEB 结构体获取 LdrLdr 获取 InMemoryOrderModuleListFlink 一次将取出表头,在固定的偏移处可以取出程序基地址Flink 3次将取出第三项,在同样的偏移处可以取出 Kernel32.dll 的基地址编译成可执行文件并运行:
1 | gcc poc.c |
得到输出:
1 | Program base: 0000000000400000 |
发现与在 Windbg 中得到的一致。
这证明:我们可以通过编写 C 代码获得被加载模块的基地址。更进一步地,我们的 C 代码经过编译后反汇编得到的汇编代码简单清晰,这意味着我们可以编写比较简单的汇编来实现这一目标。换言之,我们可以在 shellcode 中实现这一目标从而绕过 ASLR。
夏季学期课程的小组作业,是要开发一个基于Linux内核模块的包过滤防火墙。主要有两部分的任务:
配置程序
运行在应用层,用来配置过滤规则,包括协议类型、IP地址、端口号、开始和结束时间、是否启用规则等。
Linux内核模块
运行在内核层,完成包过滤防火墙的功能,该模块借助注册Netfilter钩子函数的方式来实现对数据包的过滤和控制。
我主要负责了第一部分的任务:开发一个友好的包过滤规则的配置和管理界面(GUI部分,CLI部分由组里另一位同学负责)。支持包过滤的规则导入、导出,添加、编辑、 删除、搜索等功能。应用界面如下:
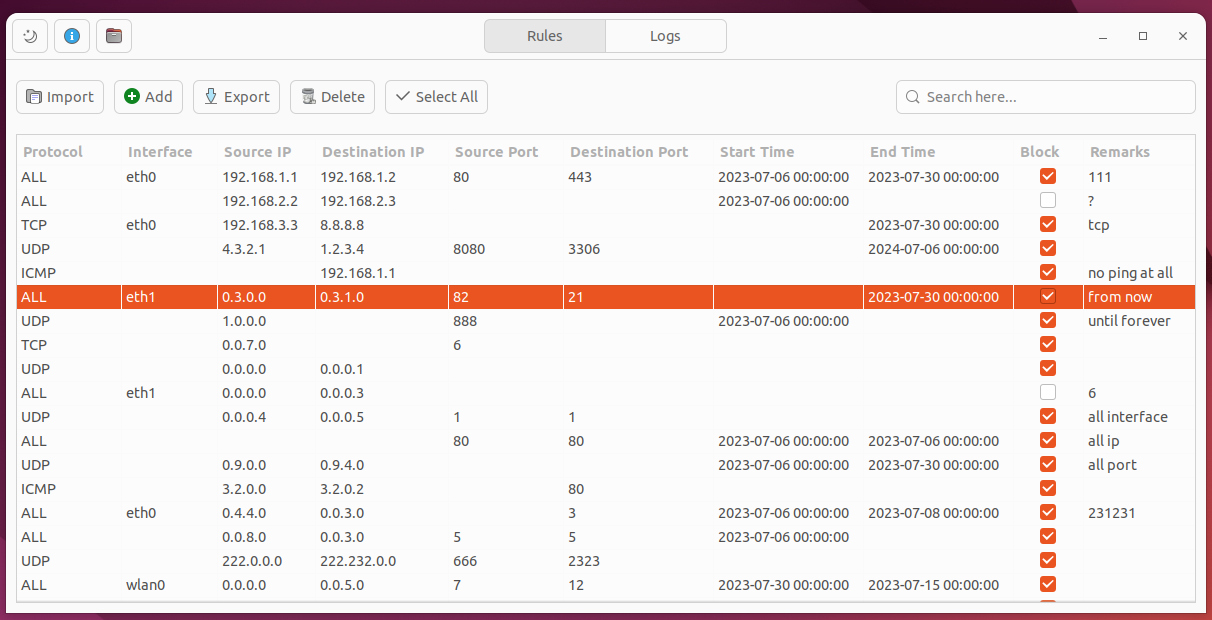
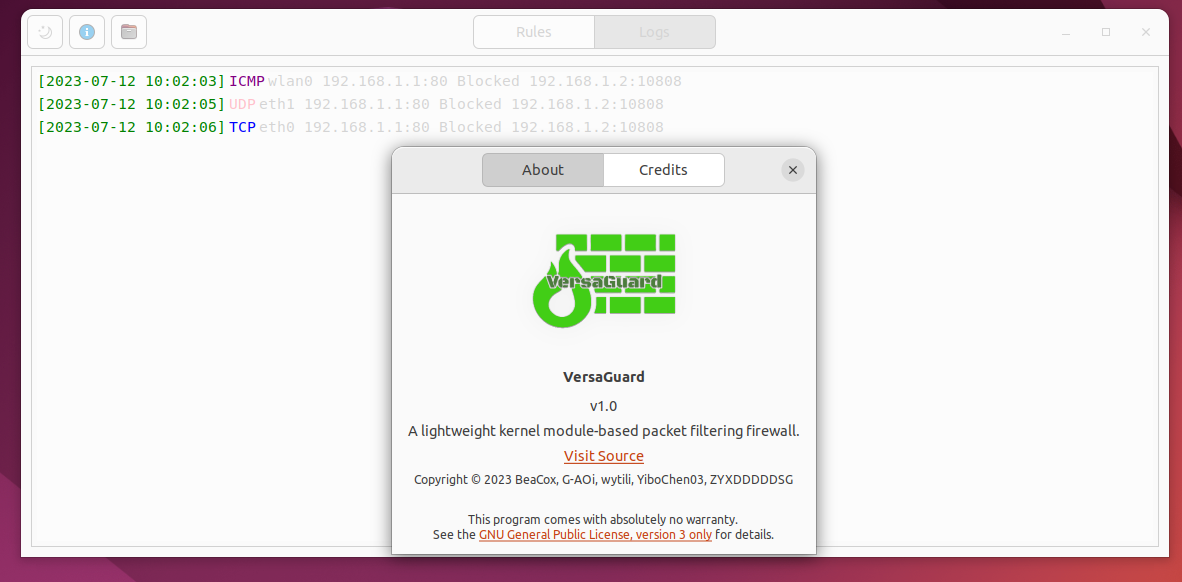
谈不上好看,但也不至于很丑。
GTK和QT是非常有名的两个GUI库,当然QT应该是更有名些。GTK和QT的优势对比如下:
最终我是选择了GTK3进行GUI开发,原因如下:
GTK相比QT的一个最大劣势就是文档更少、社区也更不活跃。B站和YouTube搜索QT,有非常多的教程,而GTK相对来说就比较少了。另外GTK4已经问世数年,但是教程大多还是GTK3。之前提到用来设计GTK应用UI的glade,支持的最高GTK版本也是GTK3。
好在对于这样一个简单的GUI应用,只需要入门GTK便可。学习一样工具,我总是喜欢边学边做。因此视频+文档的组合往往是更适合我的。在我学习GTK开发的过程中,主要参考了以下资源:
YouTube上的GTK & glade开发教程,没有涵盖GTK的所有类,但对入门来说够用而且友好。
更多时候我其实是直接看源代码学习,视频节奏有些拖沓,一旦理解GTK和glade是怎样工作的,看代码会是更高效的解决方法。
文档很全面,但只有英文。
ChatGPT
文档没写全的、视频没讲到的可以问问GPT。看看思路可以,3.5写出来的代码可能不能直接用。
使用GTK & glade开发,主要是应用UI设计和功能实现分离的思想。
在glade应用中设计UI
哪里是按钮,哪里需要输入框,哪里需要列表等等,需要提前构思好。
在glade应用中连接信号(signals)
所谓信号,就是当用户与界面发生某种特定的交互时,应用程序便会知悉,并可根据这种信号回调对应的函数、传入特定的数据进行特定的操作。可以在glade中连接信号并指定对应的回调函数,以及需要传入的数据。这样在后续功能实现时,只需将这些函数的功能实现即可,也很好地实现了模块化。
编写GTK代码
主要是实现之前在glade中指定的回调函数。另外,一些用于提示用户的对话框也可以直接用代码生成。
编译程序
在开发阶段,一般从glade文件加载builder(gtk_builder_new_from_file),并使用gcc的-export-dynamic参数。这样一来,修改glade文件后无需重新编译就可以看到新的UI。
而在生产环境中,不能使用上述方法。因为上述方法编译的应用程序需要依赖glade文件运行,而一般用于生产环境的应用程序需要将glade文件一同编译成最后的二进制程序。因此要从资源中加载builder(gtk_builder_new_from_resource)。因此首先要把glade文件编译成资源,这个过程需要用到glib-compile-resources工具。具体方法可以参照Linux Gtk Glade Programming Part 34: Embedding resources in your app。
TreeView
GTK中的TreeView以及ListBox是非常重要的组件,适合用于用户与系统的数据交互,区别在于TreeView可以有多层父子结构,而ListBox只有单层。
Log功能
Log功能的第一版思想是:每隔一段时间(如1s)监测日志文件的变化,当日志文件大小发生改变时,将新增的内容显示在应用的TextView当中。但是如果使用一个线程,会导致应用要轮流处理与用户的交互和日志文件的监测,而日志文件又需要频繁监测,造成较差的用户体验。因此为监测日志文件变化的功能单独创建一个线程进行处理。
但是线程需要应对一系列互斥与共享的问题,因此我换了一种实现方法。
第二版的思想是:使用GFileMonitor来监测文件的变化,当文件变化时,会发出一个信号,GTK应用能捕捉这个信号并做出相应的处理。
GFileMonitor VS 多线程:
优点:
缺点:
很抱歉长时间未更新! ?
在群里和小伙伴们BB了一顿系统,写篇文章记录一下。本文排名分先后。
PS:本文资料来源:百度百科,知乎。
作为世界排名第一的操作系统,也作为首个介绍对象。
MicrosoftWindows操作系统是美国微软公司研发的一套操作系统,它问世于1985年,起初仅仅是Microsoft-DOS模拟环境,后续的系统版本由于微软不断的更新升级,不但易用,也当前应用最广泛的操作系统。
Windows采用了图形化模式GUI,比起从前的Dos需要输入指令使用的方式,更为人性化。随着计算机硬件和软件的不断升级,微软的 Windows也在不断升级,从架构的16位、32位再到64位,系统版本从最初的 Windows1.0到大家熟知的 Windows95、 Windows98、 Windows2000、 Windows XP、 Windows Vista、 Windows7、Windows8、Windows8.1、Windows 10和 Windows Server服务器企业级操作系统,不断持续更新,微软一直在致力于Windows操作系统的开发和完善。
相对于其他的操作系统,win的入门门槛比较低,适合新手。
win初代的底层使用Unix,接下来就全部都是采用自家的NT。目前来说,桌面OS中 Windows 系统的占有率大约 76.52%,macOS 则是 18.99%。
实际上 Windows 系统并不是微软的第一个操作系统,在 Windows 系统之前,大多数电脑都使用微软的 MS-DOS(微软磁盘操作系统)。MS-DOS 没有图形界面,用起来就像现在的 CMD 命令提示符,所有操作都通过一行行代码实现。因为有 IBM 的扶持,MS-DOS 几乎霸占了当时整块操作系统市场。
直到有一天,苹果创始人乔布斯做出了可能是他一生最后悔的决定:向微软创始人比尔盖茨炫耀苹果最新型的麦金塔电脑(Macintosh),并希望微软能为麦金塔电脑开发软件。//如果他还在世能看到我这篇文章肯定要骂娘?乔布斯一直瞧不起比尔盖茨就是这个原因。
麦金塔电脑搭载一个图形用户界面,可使用鼠标灵活的与系统交互,被认为是首款将 GUI 成功商品化的个人电脑。
在麦金塔电脑正式发布一年后的 1985 年,微软仿造出了第一款有图形界面的操作系统,并取名叫做 Windows 1.0。用户可以更高效的查看文件,执行简单操作。
Windows 1.0 界面它还具有「多任务」和「在程序之间传输数据」的功能,这是 Windows 系统的第一个功能。
和麦金塔的系统一样,Windows 1.0 页附带了很多应用程序,例如Windows Write(文字处理软件)、画图、时钟、日历、记事本、文件管理器,甚至一款叫做 Reversi 的游戏。
不过 Windows 1.0 的软件窗口不能重叠,几乎就是以微软的风格重置了麦金塔的系统。
{x} 哦对了,忘了一件重要的事!
最早发明图形视窗操作系统的,是当年的技术先锋施乐公司。虽然图形界面是创造性的产品,相比于DOS系统,简单又酷炫,但是由于该系统既不成熟,也不实用,只有技术精英才会尝试。
Windows 偷了麦金塔,其实麦金塔也是偷自施乐公司的GUI。
两年后微软将 Windows 更新到 2.0 版本,此版本让软件窗口可以重叠,还可调整窗口大小已节约屏幕空间,另外还有一些简单的键盘快捷键和对 VGA 图形的支持。
3.0 版本是 Windows 一个重要的里程碑,它支持 256 色显示,使用虚拟内存欺骗程序,以达到更高效多任务处理。因为强大的多任务处理能力,Windows 的市场占有率飙升,从此一发不可收拾。
自此,Windows 已经走过 10 个年头,离开 IBM 后的第一个版本,Windows「整容」归来。
Windows 95 在 GUI 方面改进非常大,Windows 系统的界面布局基本在这一代定型,经典的「开始菜单」按钮和 InternetExplorer 浏览器也是这个在这个版本加入。
Windows 98 改进并不多,主要是对 fat-32 磁盘格式有了更好的支持,磁盘分区允许大于2GB。
Windows 98 界面这是一个 16 位和 32 位混合的系统,加上它老旧的 Windows 9x 内核,导致系统很容易出错,蓝屏几率很高。
不稳定 + 没有新意,Windows98 收获了一波差评如潮。
这一年又是 Windows 重要的里程碑,微软在这一年发布了两款 Windows 系统。
其中 2000 版本也就是我们现在用的 Windows 系统的前身,它首次采用 NT 内核,着重于可访问性,大大提升了用户对系统的权限。著名的粘滞键(快速按Shift五次激活)也是在这个版本加入。
{alert type="info"}
另外还有很少人知道的 Windows ME(千禧年特别版)。它继续沿用了 Windows 98 的 9x 内核。可想而知 9x 内核的不稳定性也被沿用下来了。Windows ME 最终入选「有史以来最辣鸡的25个科技产品」,被誉为 Windows 系统的黑历史。
即便饱受诟病但 Windows ME 还是为我们留下了一些好东西,比如系统还原功能(不过 ME 的还原连病毒也会一并还原)
{/alert}
经典的「叉屁」系统有家庭版和专业版两个版本,宣告微软正式放弃 9x 内核。
XP 的界面称得上是一次革新,鲜艳的配色,圆润的UI和绿色的开始菜单和青天绿草。
不过XP现在有了新的意思,这里不多做解释。
Windows XP 界面XP 还是第一款提供 64 位的 Windows 系统。当时很流行 CD,所以 XP 系统也加入了 CD 刻录软件,还有桌面搜索,远程桌面等。
最重要的是它非常非常非常稳定,这也是为什么现在还有很 XP 钉子户的原因。
XP 是寿命最长的 Windows 系统(13年),被誉为微软的 Messiah(救世主),它的地位可想而知。
Vista 最大的卖点之一是新设计的界面(Aero Glass)但是性能要求过高,售价高昂。
尽管「用户帐户控制」功能前所未有的安全性,但这个功能强制开启不能关闭,让用户非常讨厌。
这点我在群里和小伙伴讨论了很久。
微软在 Vista 上步子迈的太大,扯到了蛋蛋。在用户调查中,只有 8% 的人表示满意(XP是41%满意),尽管如此Vista 的首发销量却比XP好,有2000 万份,不过很多用户体验后又降级到 XP。
继续使用 Vista 的用户大多是游戏玩家,因为它是第一个包含 DirectX 10(用于 3D 图像处理) 的系统,
另外 Vista 还为我们留下了 Windows Defender(根据安全软件排名,这个系统自带的杀毒软件非常OK,360这边就不建议大家安装了)。
两年后微软发布了 Windows 7,旨在解决 Vista 存在的问题。Windows 7 稍微改进了界面,可自主关闭「用户帐户控制」通知,便饱受好评。
Windows 8 界面风格再次大改,它的重点是触摸屏设备,也就是微软的跨平台计划,为此开始菜单被设计成了一个铺满「瓷砖」的界面,这使许多人感到不适应。
这是我2013买的第一台电脑自带的系统//用的实在不习惯
这是最近一代的 Windows 系统,也是微软的转型之作,以往的微软都是卖软件赚取,从Windows 10 开始微软的业务从软件销售专为云服务。所以 Windows 10 发布之初做出了免费送活动,Windows7 - 8.1 用户可以免费升级到 Windows 10,上亿用户免费洗白。
mac也在这年增加了对win系统的支持,使用启动转换助手可以直接安装win10,我记得之前我也写过这样的文章,但是在迁移过程中被删除了。
Windows 10 的重心回到桌面端,引入了个人助理小娜(Cortana),支持生物解锁(指纹和面部),自动搜索安装驱动,同时更新策略变为每年两次大更新,并且永久免费。
Windows 11是由微软公司(Microsoft)开发的操作系统,应用于计算机和平板电脑等设备 。于2021年6月24日发布,2021年10月5日发行。
Windows 11提供了许多创新功能,增加了新版开始菜单和输入逻辑等,支持与时代相符的混合工作环境,侧重于在灵活多变的体验中提高最终用户的工作效率 。
截至2022年6月15日,Windows 11正式版已更新至22000.739版本 ;预览版已更新至25140 版本 。
2022年5月19日,微软宣布,Windows 11已可以广泛部署(broad deployment),意味着任何拥有符合Windows 11最低配置要求的PC都应该能够安装该系统。
2022年7月24日,微软正式上架了Win11的购买选项,Win11家庭版的国行售价为1088元,专业版则仅支持从Win10进行升级,无法直接购买。
