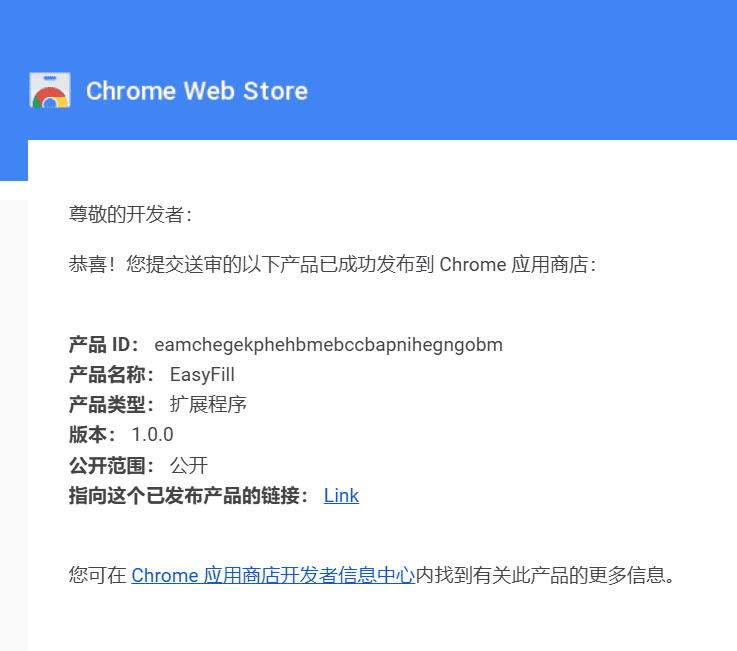
之前我写过一篇《利用Go+Github Actions写个定时RSS爬虫》 来实现这一目的,主要是用 GitHub Actions + Go 进行持续的 RSS 拉取,再把结果上传到 GitHub Pages 站点
但是遇到一些网络延迟、TLS 超时问题,导致订阅页面访问速度奇慢,抓取的数据也不完整,后来时断时续半个月重构了代码,进一步增强了并发和容错机制
在此感谢 GPT o1 给予的帮助,我已经脱离老本行很多年了,重构的压力真不小,有空就利用下班的时间进行调试,在今天凌晨 03:00 我终于写完了
1. 为什么要重构
旧版本主要基于 GitHub Actions 的定时触发,抓取完后把结果存放进 _data/rss_data.json 然后 Jekyll 就可以直接引用这个文件来展示订阅,但是这个方案有诸多不足:
网络不稳定导致的抓取失败
由于原先的重试机制不够完善,GitHub Actions 在国外,RSS 站点大多在国内,一旦连接超时就挂,一些 RSS 无法成功抓取
单线程串行,速度偏慢
旧版本一次只能串行抓取 RSS,效率低,数量稍多就拉长整体执行时间,再加上外网到内地的延时,更显迟缓
日志不够完善
出错时写到的日志文件只有大概的错误描述,无法区分是解析失败、头像链接失效还是RSS本身问题,排查不便
访问速度影响大
这是主要的重构原因!在旧版本里,抓取后的 JSON 数据是要存储到 Github 仓库的,虽然有 CDN 加持,但 GitHub Pages 的定时任务会引起连锁反应,当新内容刷新时容易出现访问延迟,极端情况下网页都挂了
2. 主要思路
2.1 整体流程
先看个简单的流程图
+--------------------------+
| 1. 读取RSS列表(双端可选) |
+------------+-------------+
|
v
+---------------------+
| 2. 并发抓取RSS,限流 |
| (max concurrency) |
+-------+-------------+
|
v
+------------------------------+
| 3. 指数退避算法 (重试解析失败) |
+------------------------------+
|
v
+-------------------+
| 4. 结果整合排序 |
+--------+----------+
|
v
+-------------------------+
| 5. 上传 RSS (双端可选) |
+-------------------------+
|
v
+--------------------+
| 6. 写日志到GitHub |
+--------------------+
并发抓取 + 限流
指数退避重试
灵活存储
日志自动清理
2.2 指数退避
上一次写指数退避,还是在养老院写PHP的时候,时过境迁啊,这段算法我调试了很久,其实不难,也就是说失败一次,就等待更长的时间再重试,配置如下:
最大重试次数: 3
初始等待: 1秒
等待倍数: 2.0
也就是说失败一次就加倍等待,下次若依然失败就再加倍,如果三次都失败则放弃处理
// fetchAllFeeds 并发抓取所有RSS链接,返回抓取结果及统计信息
//
// Description:
//
// 该函数读取传入的所有RSS链接,使用10路并发进行抓取
// 在抓取过程中对解析失败、内容为空等情况进行统计
// 若抓取的RSS头像缺失或无法访问,将替换为默认头像
//
// Parameters:
// - ctx : 上下文,用于控制网络请求的取消或超时
// - rssLinks : RSS链接的字符串切片,每个链接代表一个RSS源
// - defaultAvatar : 备用头像地址,在抓取头像失败或不可用时使用
//
// Returns:
// - []feedResult : 每个RSS链接抓取的结果(包含成功的Feed及其文章或错误信息)
// - map[string][]string : 各种问题的统计记录(解析失败、内容为空、头像缺失、头像不可用)
func fetchAllFeeds ( ctx context . Context , rssLinks [] string , defaultAvatar string ) ([] feedResult , map [ string ][] string ) {
// 设置最大并发量,以信道(channel)信号量的方式控制
maxGoroutines := 10
sem := make ( chan struct {}, maxGoroutines )
// 等待组,用来等待所有goroutine执行完毕
var wg sync . WaitGroup
resultChan := make ( chan feedResult , len ( rssLinks )) // 用于收集抓取结果的通道
fp := gofeed . NewParser () // RSS解析器实例
// 遍历所有RSS链接,为每个RSS链接开启一个goroutine进行抓取
for _ , link := range rssLinks {
link = strings . TrimSpace ( link )
if link == "" {
continue
}
wg . Add ( 1 ) // 每开启一个goroutine,对应Add(1)
sem <- struct {}{} // 向sem发送一个空结构体,表示占用了一个并发槽
// 开启协程
go func ( rssLink string ) {
defer wg . Done () // 协程结束时Done
defer func () { <- sem }() // 函数结束时释放一个并发槽
var fr feedResult
fr . FeedLink = rssLink
// 抓取RSS Feed, 无法解析时,使用指数退避算法进行重试, 有3次重试, 初始1s, 倍数2.0
feed , err := fetchFeedWithRetry ( rssLink , fp , 3 , 1 * time . Second , 2.0 )
if err != nil {
fr . Err = wrapErrorf ( err , "解析RSS失败: %s" , rssLink )
resultChan <- fr
return
}
if feed == nil || len ( feed . Items ) == 0 {
fr . Err = wrapErrorf ( fmt . Errorf ( "该订阅没有内容" ), "RSS为空: %s" , rssLink )
resultChan <- fr
return
}
// 获取RSS的头像信息(若RSS自带头像则用RSS的,否则尝试从博客主页解析)
avatarURL := getFeedAvatarURL ( feed )
fr . Article = & Article {
BlogName : feed . Title ,
}
// 检查头像可用性
if avatarURL == "" {
// 若头像链接为空,则标记为空字符串
fr . Article . Avatar = ""
} else {
ok , _ := checkURLAvailable ( avatarURL )
if ! ok {
fr . Article . Avatar = "BROKEN" // 无法访问,暂记为BROKEN
} else {
fr . Article . Avatar = avatarURL // 正常可访问则记录真实URL
}
}
// 只取最新一篇文章作为结果
latest := feed . Items [ 0 ]
fr . Article . Title = latest . Title
fr . Article . Link = latest . Link
// 解析发布时间,如果 RSS 解析器本身给出了 PublishedParsed 直接用,否则尝试解析 Published 字符串
pubTime := time . Now ()
if latest . PublishedParsed != nil {
pubTime = * latest . PublishedParsed
} else if latest . Published != "" {
if t , e := parseTime ( latest . Published ); e == nil {
pubTime = t
}
}
fr . ParsedTime = pubTime
fr . Article . Published = pubTime . Format ( "02 Jan 2006" )
resultChan <- fr
}( link )
}
// 开启一个goroutine等待所有抓取任务结束后,关闭resultChan
go func () {
wg . Wait ()
close ( resultChan )
}()
// 用于统计各种问题
problems := map [ string ][] string {
"parseFails" : {}, // 解析 RSS 失败
"feedEmpties" : {}, // 内容 RSS 为空
"noAvatar" : {}, // 头像地址为空
"brokenAvatar" : {}, // 头像无法访问
}
// 收集抓取结果
var results [] feedResult
for r := range resultChan {
if r . Err != nil {
errStr := r . Err . Error ()
switch {
case strings . Contains ( errStr , "解析RSS失败" ) :
problems [ "parseFails" ] = append ( problems [ "parseFails" ], r . FeedLink )
case strings . Contains ( errStr , "RSS为空" ) :
problems [ "feedEmpties" ] = append ( problems [ "feedEmpties" ], r . FeedLink )
}
results = append ( results , r )
continue
}
// 对于成功抓取的Feed,如果头像为空或不可用则使用默认头像
if r . Article . Avatar == "" {
problems [ "noAvatar" ] = append ( problems [ "noAvatar" ], r . FeedLink )
r . Article . Avatar = defaultAvatar
} else if r . Article . Avatar == "BROKEN" {
problems [ "brokenAvatar" ] = append ( problems [ "brokenAvatar" ], r . FeedLink )
r . Article . Avatar = defaultAvatar
}
results = append ( results , r )
}
return results , problems
}
2.3 并发抓取 + 限流
为避免一下子开几十上百个协程导致阻塞,可以配合一个带缓存大小的 channel
maxGoroutines := 10
sem := make ( chan struct {}, maxGoroutines )
for _ , rssLink := range rssLinks {
// 启动 goroutine 前先写入一个空 struct
sem <- struct {}{}
go func ( link string ) {
// goroutine 执行结束后释放 <-sem
defer func () { <- sem }()
fetchFeedWithRetry ( link , parser , 3 , 1 * time . Second , 2.0 )
// ...
}( rssLink )
}
3. 对比旧版本的改进
容错率显著提升
遇到网络抖动、超时等问题,能以10路并发限制式自动重试,很少出现直接拿不到数据
抓取速度更快
以 10 路并发为例,对于数量多的 RSS,速度提升明显
日志分类更细
分清哪条 RSS 是解析失败,哪条头像挂了,哪条本身有问题,后续维护比只给个403 Forbidden方便太多
支持 COS
可将最终 data.json 放在 COS 上进行 CDN 加速;也能继续放在 GitHub,视自己需求而定
自动清理过期日志
每次抓取后检查 logs/ 目录下 7 天之前的日志并删除,不用手工清理了
4. Go 生成的 JSON 和日志长啥样
4.1 RSS
抓取到的文章信息会按时间降序排列,示例:
{
"items" : [
{
"blog_name" : "obaby@mars" ,
"title" : "品味江南(三)–虎丘塔 东方明珠" ,
"published" : "10 Mar 2025" ,
"link" : "https://oba.by/2025/03/19714" ,
"avatar" : "https://oba.by/wp-content/uploads/2020/09/icon-500-100x100.png"
},
{
"blog_name" : "风雪之隅" ,
"title" : "PHP8.0的Named Parameter" ,
"published" : "10 May 2022" ,
"link" : "https://www.laruence.com/2022/05/10/6192.html" ,
"avatar" : "https://www.laruence.com/logo.jpg"
}
],
"updated" : "2025年03月11日 07:15:57"
}
4.2 日志
程序每次运行完毕后,把抓取统计和问题列表写到 GitHub 仓库 logs/YYYY-MM-DD.log:
[2025-03-11 07:15:57] 本次订阅抓取结果统计:
[2025-03-11 07:15:57] 共 25 条RSS, 成功抓取 24 条.
[2025-03-11 07:15:57] ✘ 有 1 条订阅解析失败:
[2025-03-11 07:15:57] - https://tcxx.info/feed
[2025-03-11 07:15:57] ✘ 有 1 条订阅头像无法访问, 已使用默认头像:
[2025-03-11 07:15:57] - https://www.loyhome.com/feed
5. 照葫芦画瓢
如果你也想玩玩 LhasaRSS
准备一份 RSS 列表 (TXT):
格式:每行一个 URL
配置好环境变量 :
默认所有数据保存到 Github,所以 COS API 环境变量不是必要的
env :
TOKEN : ${{ secrets.TOKEN }} # GitHub Token
NAME : ${{ secrets.NAME }} # GitHub 用户名
REPOSITORY : ${{ secrets.REPOSITORY }} # GitHub 仓库名
TENCENT_CLOUD_SECRET_ID : ${{ secrets.TENCENT_CLOUD_SECRET_ID }} # 腾讯云 COS SecretID
TENCENT_CLOUD_SECRET_KEY : ${{ secrets.TENCENT_CLOUD_SECRET_KEY }} # 腾讯云 COS SecretKey
RSS : ${{ secrets.RSS }} # RSS 列表文件
DATA : ${{ secrets.DATA }} # 抓取后的数据文件
DEFAULT_AVATAR : ${{ secrets.DEFAULT_AVATAR }} # 默认头像 URL
RSS_SOURCE ${{ secrets.RSS_SOURCE }} # 可选参数 GITHUB or COS
SAVE_TARGET ${{ secrets.SAVE_TARGET }} # 可选参数 GITHUB or COS
部署并运行
只需 go run . 或在 GitHub Actions workflow_dispatch 触发
运行结束后,就会在 data 文件夹更新 data.json,日志则写进 GitHub logs/ 目录,并且自动清理旧日志
注:如果你依旧想完全托管在 COS 上,需要把 RSS_SOURCE 和 SAVE_TARGET 都写为 COS,然后使用 GitHub Actions 去调度
相关文档