前言
啊哈,当你看到这篇文章的时候,新的网站应该已经上线了!
虽然界面外观没有太大的变化,但是内在却是处处不同。几乎全部的代码都删改了一遍,重新规范了所有的类和函数的命名规则,并完善了注释,尽可能地优化了性能,修复了无数的bug。
最最最重要的更新就是本站的多语言功能升级到8种语言了!
这八种语言分别是:简体中文、英语、法语、德语、日语、韩语、俄语和西班牙语,这样来自不同语言的搜索引擎都会收录我的网站啦。
本文的主要内容是关于:我需不需要要重构代码?以及重构代码中可能遇到的问题以及注意事项。
我为什么要重构?
1、提升访客停留时间
在我自己搭建的 umami 访客统计中,我看到很多来自欧洲和非洲的访客停留时间都非常的短,除了文章内容没有吸引力的原因外,另一个很显而易见的原因是因为语言不通所导致的。
根据我我在网络上查询到的资料,绝大部分来自小语种国家的人一般都使用英语作为第二语言。所以目前这八种语言至少可以应对全球80%的访客。
在可以预见的未来,本站支持的多语言数量并不会再增加。
2、清除冗余代码
我在将网站迁移到Flask 的那篇文章中已经说明了,这整个前后端并不是为了博客特意开发的,而是一个失败项目的回收再利用,这也是我迫切想要重构网站系统的原因之一。
在将其修改为博客前后端程序的时候,因为编码技能的不熟练以及编码水平有限,很多的逻辑写的比较凌乱和零散。可能会发生a引用b,b又引用c,c有的时候又会引用a,造成这套系统冗余代码非常多,而且还不能一删了之,因为有些逻辑链我都理不清了。
而且为了让它能够更加适合我的使用习惯以及新增更多的功能,在这基础上,不断的叠加代码导致系统越来越臃肿,最终变成了一座屎山,而现在想要新增功能,特别是针对底层逻辑的修改,几乎就是不可能的任务。
3、优化性能
最初设计的时候是为了应对以万为单位的数据量设计的,所以是用的是ES。但我觉得目前以及可以看到的未来我的文章数也不会以万为单位。哪怕我天天写,一年才三百多篇,算上多语言版本也就才两千多篇,五年才能破万。
所以我打算使用 Sqlite 作为网站的数据库,这样对于性能的需求应该能大幅下降。
4、增加新功能
本站一开始就支持了多语言,但这个多也就只是两种:中文和英文。
但我在后台看到我甚至有来自 yandex 的引荐,那我就在想了,也许我可以直接提供俄语版本的博客内容,这样可以让yandex 收录更多的文章,并因此来带更多的流量,Google了一下,干脆提供所有主要语言的版本得了,免得以后还要增加其他的语言。
有的时候啊,想法一出来,就想立马把它给实现,要不然会在心里一直念念不忘。我立即着手准备新增功能。
不到一个小时后,我就放弃了想要在原有代码上新增功能的想法,因为我一开始在数据库结构设计上就写死了两种语言,这不仅仅是要改数据库结构,搜索模块、缓存模块、甚至RSS生成器都要重新设计😭。
稍稍一计算工作量,与其在旧的代码上修修改改,还不如完全重新开发一个呢。说搞就搞,我真的是一刻也停不下来,立刻在电脑上新建了一个项目目录,开始重构代码。
我是如何做的?
这里简单讲讲我是如何做的,具体的各种实现,我会后面再单独开一篇讲讲。
1、备份数据
各位,备份数据真的是重中之重,丢失了数据真的让人难以接受。在做任何重要操作前,务必备份数据。
我讲讲我在五一节期间遇到的真实案例吧。因为大家都要出游,我也不例外。当我在等待换乘列车的时候,拿出笔记本远程连接到家里的 Windows 使用 VScode remote 连接到 Linux 虚拟机上写代码。可能路径很绕,但 VScode remote 真的救了我的数据。
当时的情况是我对某个 .json 测试文件测试完毕了,需要将它从项目目录删除,不知道怎么回事同时选择到了 app.py 文件,然后 Delete + Enter 操作行云流水。屏幕一闪发现刚刚在写的代码页面怎么没了,反应过来的时候人都傻了。
最后找回文件的方法是:在同目录新建一个同名文件,使用时间线功能恢复到之前的版本。
2、重新设计数据库结构
我对数据库进行了彻头彻尾的改造,首先是加入了每一篇文章的语言标识,以及对应的其它语言的文章ID,这样当访客在访问某一篇文章的时候就可以使用多语言切换按钮跳转到不同的语言。
当然还是因为我的旧博客,我还是兼容了之前的链接格式。
3、编码
这部分可以讲的太多了,为了支持多语言,我翻译了网站上的所有显性文本,并根据访客的语言自动使用最合适的。
为了更好的翻译文章,在后端内置了azure 的翻译器,写完中文后,点击即可全文翻译,然后人工校对以下格式就可以发布了,节省了我大量的时间。
为了让我更好的管理文章,搞了个类似聚合的功能,对于我只看得到中文的文章,而其他语言的文章都在这篇文章的子页面下。
为了 SEO ,新版博客的每一个页面都是静态页面,移除了所有的 Ajax 异步加载页面元素功能,这样对于爬虫也更加友好。
为了......
更多的新功能和技术细节后续我会在新文章里单独详细介绍。
后记
距离上一次更新过去了差不多三周多,打破了我之前为自己顶的目标【周更博客】,但我认为这是值得的,不仅仅满足了自己的成就感,还让我的各种技能得到了充分的锻炼。ps:后续更新就不会影响博客文章发布了。
哦,对了,这次更新中,ChatGPT 功不可没,有大约一半的代码我都让它进行过优化,以提升可读性和性能,可能再现实问题上 ChatGPT 经常胡编乱造,但在写代码这部分能力上,它的可靠性还算可以,而且哪怕出了错,也可以将错误直接丢给它,让它继续debug。








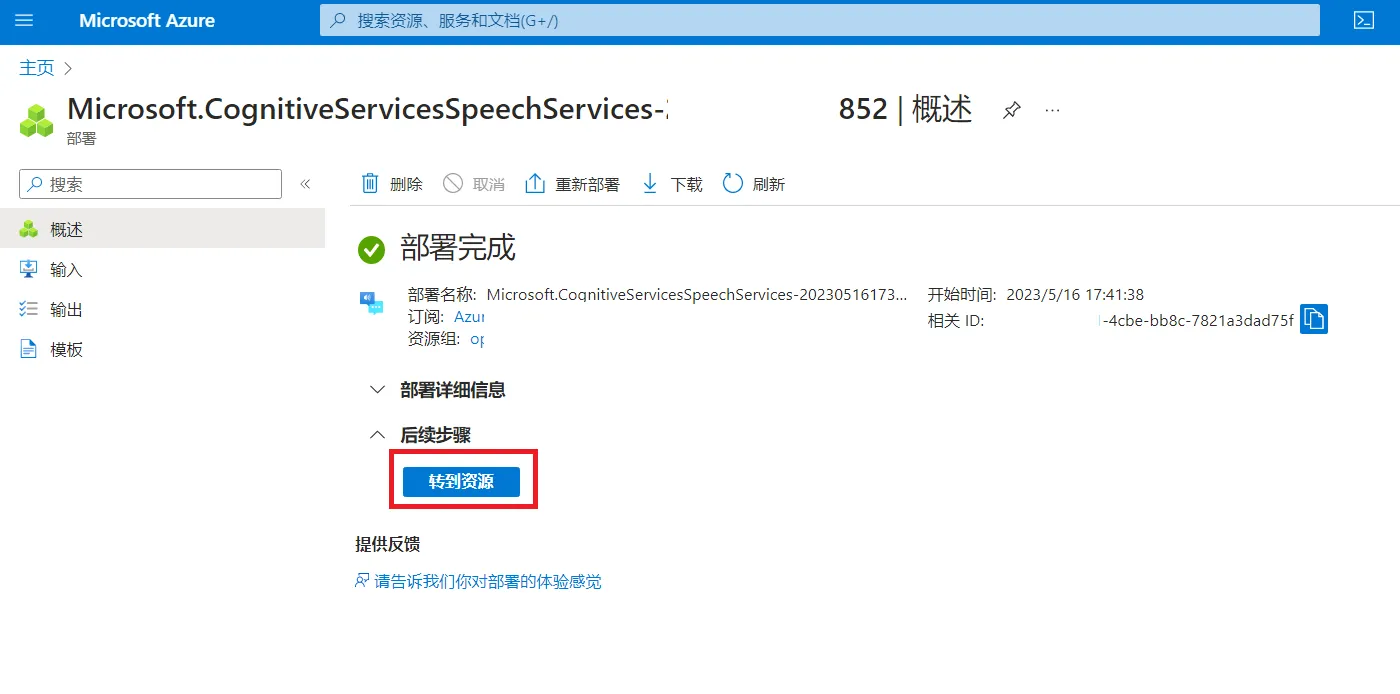
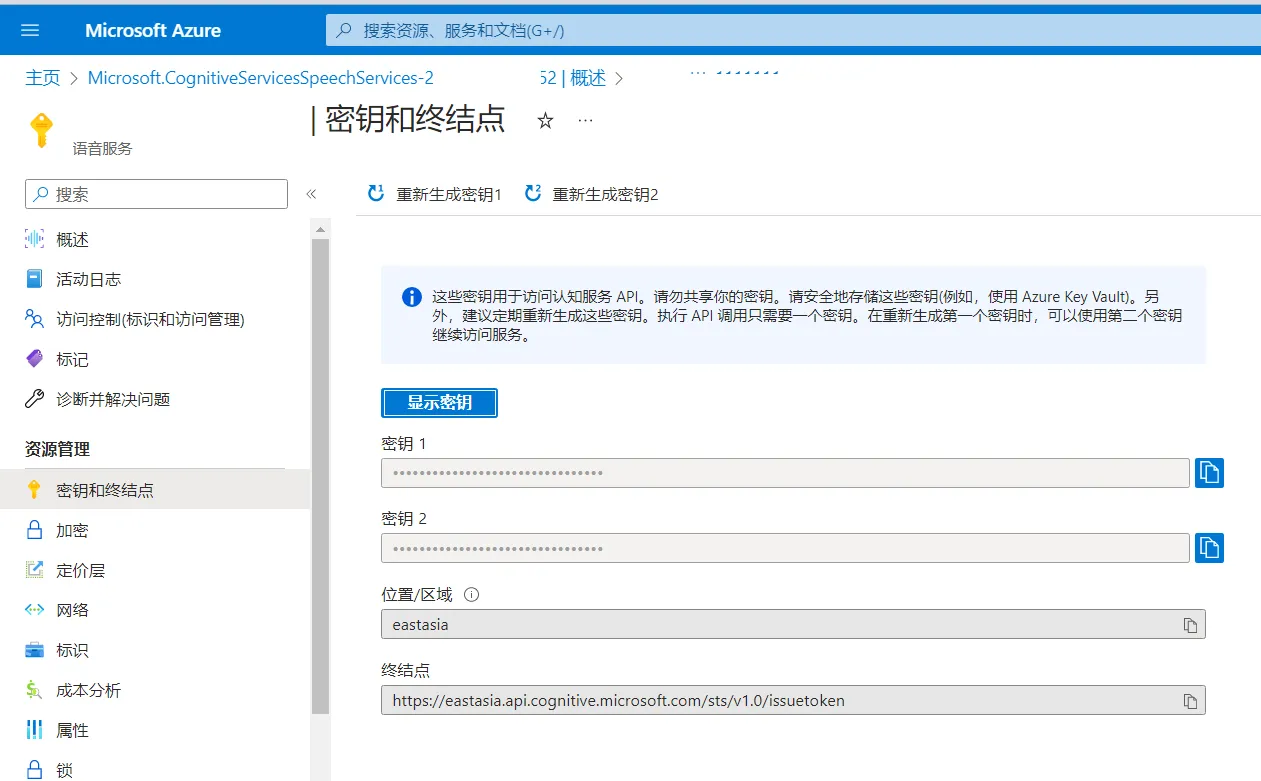
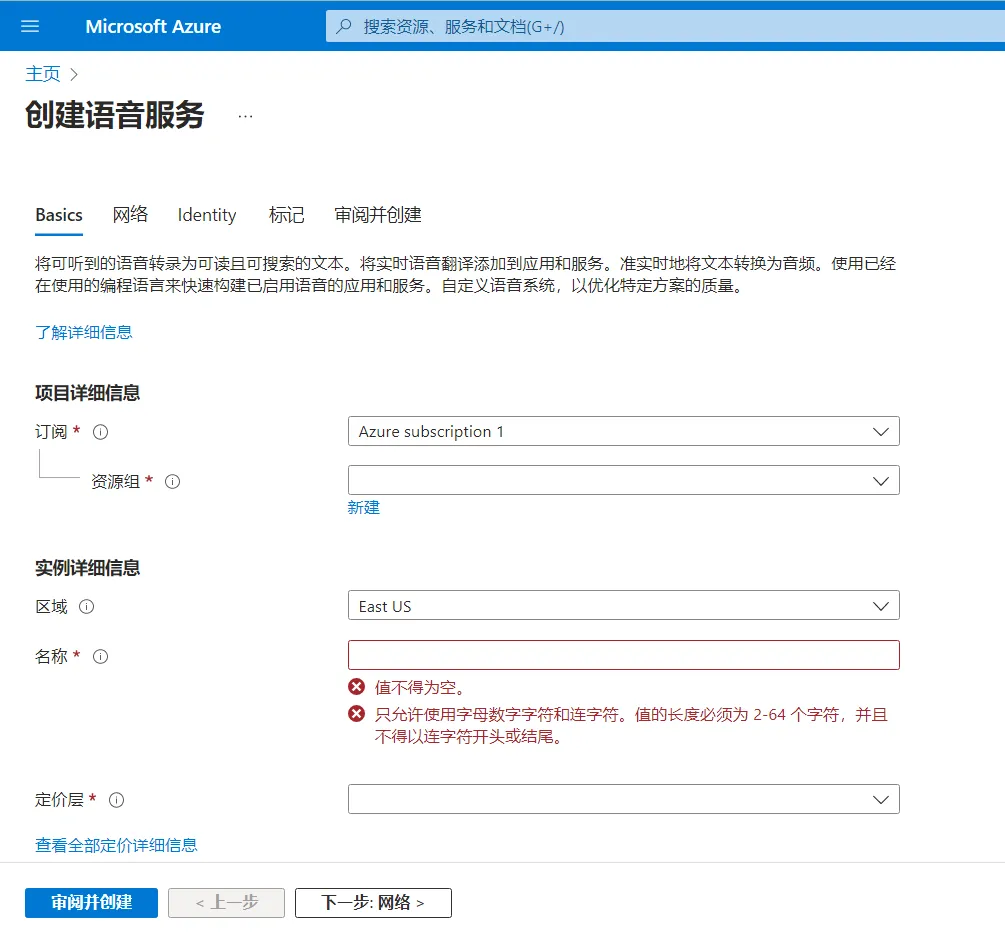 填写以下信息:
区域:选择 East Asia
名称:随便一个名字
定价层:选择免费试用(Free F0)
填写以下信息:
区域:选择 East Asia
名称:随便一个名字
定价层:选择免费试用(Free F0)